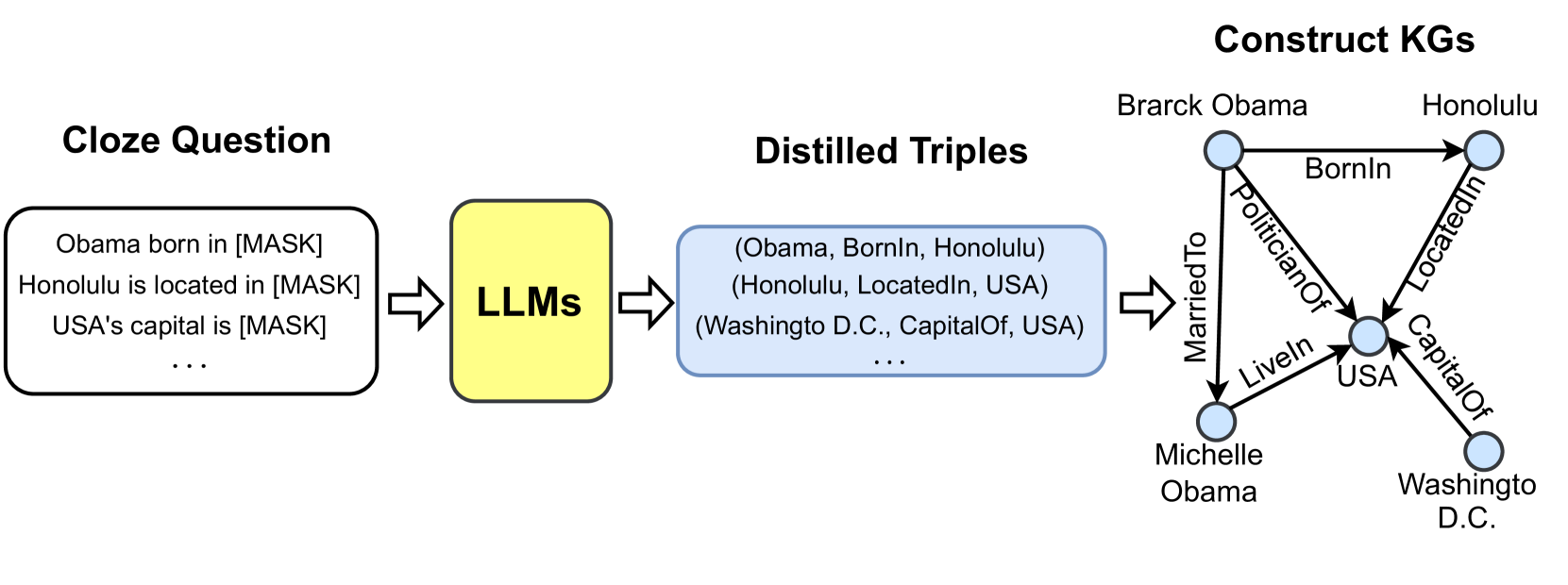
## Flowchart: Knowledge Graph Construction Pipeline
### Overview
The image depicts a three-stage pipeline for constructing knowledge graphs (KGs) from cloze-style questions. The process involves:
1. **Cloze Question Generation** (left)
2. **Triple Extraction via LLMs** (center)
3. **KG Construction** (right)
### Components/Axes
#### Left Section: Cloze Question
- **Text Box**: Contains three example cloze questions with masked entities:
- "Obama born in [MASK]"
- "Honolulu is located in [MASK]"
- "USA's capital is [MASK]"
- **Purpose**: Illustrates input format for knowledge extraction.
#### Center Section: Distilled Triples
- **Yellow Box**: Labeled "LLMs" (Large Language Models).
- **Triples Output**: Structured triples in parentheses:
- `(Obama, BornIn, Honolulu)`
- `(Honolulu, LocatedIn, USA)`
- `(Washington D.C., CapitalOf, USA)`
- **Flow**: Arrows connect the cloze questions to the triples, indicating LLM processing.
#### Right Section: Construct KGs
- **Knowledge Graph Diagram**:
- **Nodes**: Entities (e.g., "Barack Obama," "Honolulu," "USA").
- **Edges**: Relationships (e.g., "BornIn," "LocatedIn," "CapitalOf").
- **Structure**:
- "Barack Obama" → "Honolulu" (BornIn)
- "Honolulu" → "USA" (LocatedIn)
- "USA" → "Washington D.C." (CapitalOf)
- "Michelle Obama" → "USA" (Liveln)
- "Barack Obama" → "Michelle Obama" (MarriedTo)
### Detailed Analysis
- **Cloze Questions**: All masked entities are placeholders for named entities (e.g., "Honolulu" for the first mask).
- **Triples**: Each triple follows the pattern `(Subject, Predicate, Object)`.
- **KG Connections**:
- Directed edges represent relationships (e.g., "BornIn" points from subject to object).
- Central node "USA" acts as a hub for location-based relationships.
### Key Observations
- **Flow Direction**: Left-to-right progression from raw questions to structured triples to KG.
- **Entity Relationships**: The KG emphasizes geographic and relational connections (e.g., "LocatedIn," "CapitalOf").
- **No Numerical Data**: The image focuses on structural relationships, not quantitative metrics.
### Interpretation
This pipeline demonstrates how LLMs can convert unstructured cloze questions into structured knowledge graphs. The KG construction highlights:
1. **Entity Linking**: Connecting individuals (e.g., Obama) to locations (e.g., Honolulu).
2. **Hierarchical Relationships**: Geographic hierarchies (e.g., cities → countries).
3. **Semantic Roles**: Explicit roles like "BornIn" and "MarriedTo" clarify entity interactions.
The absence of numerical values suggests the focus is on qualitative knowledge representation rather than statistical analysis. The central role of "USA" in the KG underscores its importance as a geographic anchor in the example.