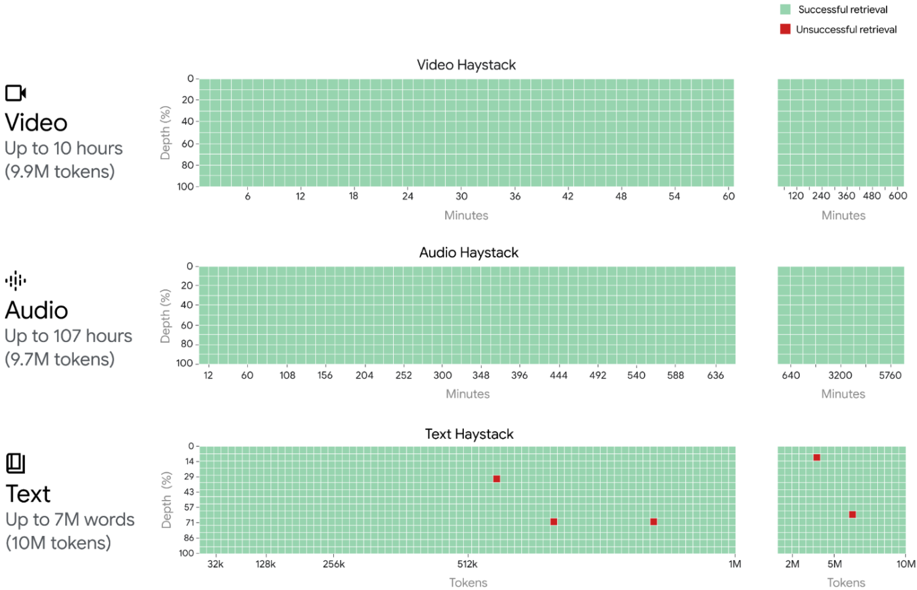
## Heatmap Series: Retrieval Success Across Modalities (Video, Audio, Text)
### Overview
The image displays three horizontally-aligned heatmap charts, each visualizing the success rate of a retrieval system across different data modalities: Video, Audio, and Text. The charts compare performance across varying depths (vertical axis) and scales of time or token count (horizontal axis). A consistent color legend is used: green indicates "Successful retrieval" and red indicates "Unsuccessful retrieval."
### Components/Axes
* **Legend:** Located at the top-right corner.
* Green square: "Successful retrieval"
* Red square: "Unsuccessful retrieval"
* **Chart Structure:** Three separate charts stacked vertically, each with its own title, axes, and data grid.
1. **Top Chart: "Video Haystack"**
* **Left Label:** Icon of a video camera, text "Video", "Up to 10 hours (9.9M tokens)".
* **Y-Axis (Left):** Label "Depth (%)". Scale runs from 0 at the top to 100 at the bottom, with markers at 0, 20, 40, 60, 80, 100.
* **X-Axis (Bottom):** Label "Minutes". The axis is split into two segments. The left segment runs from 6 to 60 minutes (markers: 6, 12, 18, 24, 30, 36, 42, 48, 54, 60). The right segment runs from 120 to 600 minutes (markers: 120, 240, 360, 480, 600).
2. **Middle Chart: "Audio Haystack"**
* **Left Label:** Icon of sound waves, text "Audio", "Up to 107 hours (9.7M tokens)".
* **Y-Axis (Left):** Label "Depth (%)". Identical scale to the Video chart (0-100).
* **X-Axis (Bottom):** Label "Minutes". The axis is split. The left segment runs from 12 to 636 minutes (markers: 12, 60, 108, 156, 204, 252, 300, 348, 396, 444, 492, 540, 588, 636). The right segment runs from 640 to 5760 minutes (markers: 640, 3200, 5760).
3. **Bottom Chart: "Text Haystack"**
* **Left Label:** Icon of a document, text "Text", "Up to 7M words (10M tokens)".
* **Y-Axis (Left):** Label "Depth (%)". Scale runs from 0 at the top to 100 at the bottom, with markers at 0, 14, 29, 43, 57, 71, 86, 100.
* **X-Axis (Bottom):** Label "Tokens". The axis is split. The left segment runs from 32k to 1M tokens (markers: 32k, 128k, 256k, 512k, 1M). The right segment runs from 2M to 10M tokens (markers: 2M, 5M, 10M).
### Detailed Analysis
* **Video Haystack Data:** The entire grid, across all depths (0-100%) and all time scales (6 to 600 minutes), is filled with green squares. This indicates a 100% successful retrieval rate for the tested video data.
* **Audio Haystack Data:** Similarly, the entire grid for audio, across all depths (0-100%) and all time scales (12 to 5760 minutes), is filled with green squares. This indicates a 100% successful retrieval rate for the tested audio data.
* **Text Haystack Data:** The grid is predominantly green but contains five distinct red squares, indicating unsuccessful retrieval events.
* **Red Square 1:** Located in the left segment. Position: Approximately at **Depth 29%** and **Tokens ~512k**.
* **Red Square 2:** Located in the left segment. Position: Approximately at **Depth 71%** and **Tokens ~512k**.
* **Red Square 3:** Located in the left segment. Position: Approximately at **Depth 71%** and **Tokens ~1M**.
* **Red Square 4:** Located in the right segment. Position: Approximately at **Depth 14%** and **Tokens ~2M**.
* **Red Square 5:** Located in the right segment. Position: Approximately at **Depth 71%** and **Tokens ~5M**.
### Key Observations
1. **Modality Performance Disparity:** There is a stark contrast between modalities. Video and Audio retrieval show perfect success (100% green) across all tested parameters. Text retrieval, while highly successful overall, exhibits specific failure points.
2. **Text Failure Pattern:** The unsuccessful retrievals in the Text Haystack are not random. They cluster at specific depths (notably 14%, 29%, and 71%) and occur at higher token counts (512k, 1M, 2M, 5M). No failures are visible in the lower token ranges (32k-256k).
3. **Scale Representation:** The charts use a split x-axis to represent a wide range of scales (from minutes to thousands of minutes, and from thousands to millions of tokens) within a compact space. The grid cells likely represent aggregated performance buckets.
### Interpretation
This visualization demonstrates the robustness of a retrieval system across different data types. The perfect scores for Video and Audio suggest the system is exceptionally reliable for processing and retrieving information from continuous, time-based media within the tested limits (up to 10 hours of video, 107 hours of audio).
The Text Haystack results are more nuanced. The high density of green indicates strong general performance, but the isolated red squares reveal specific conditions where the system fails. These failures occur at mid-to-high depth percentages and at larger document/token sizes (512k tokens and above). This could indicate:
* **System Limits:** The retrieval mechanism may have a performance threshold or encounter indexing challenges with very long text documents.
* **Complexity at Scale:** The "needle in a haystack" problem becomes demonstrably harder for text as the "haystack" (token count) grows beyond a certain point (around 500k tokens in this test).
* **Depth Sensitivity:** Failures at specific depths (like 71%) might correlate with particular structural or informational complexities within the test documents at those positions.
In summary, the data suggests the system is production-ready for audio and video retrieval within its tested bounds but may require monitoring or optimization when handling extremely large text corpora, particularly beyond the half-million token mark. The precise, repeatable pattern of text failures provides clear targets for diagnostic investigation.