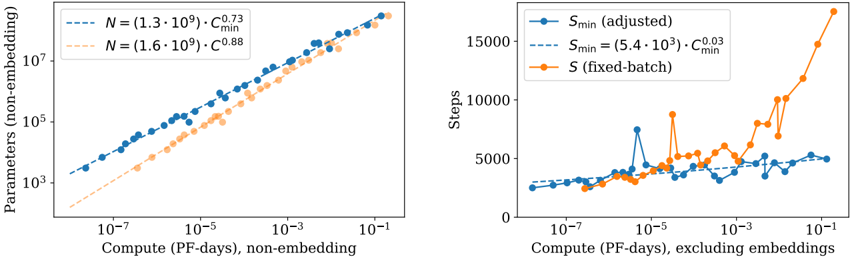
## Chart: Parameter Scaling vs. Compute
### Overview
The image presents two scatter plots comparing compute (measured in PF-days) against parameters (non-embedding) and steps, respectively. The left plot shows the relationship between compute and the number of parameters, while the right plot shows the relationship between compute and the number of steps. Both plots use a log-log scale for the x-axis (Compute) and a log scale for the y-axis (Parameters or Steps).
### Components/Axes
**Left Plot:**
* **X-axis:** Compute (PF-days), non-embedding. Logarithmic scale from approximately 10^-7 to 10^-1.
* **Y-axis:** Parameters (non-embedding). Logarithmic scale from 10^3 to 10^7.
* **Data Series 1 (Blue):** `N = (1.3 * 10^9) * C_min^0.73` (dashed line)
* **Data Series 2 (Orange):** `N = (1.6 * 10^9) * C_min^0.88` (dashed line)
**Right Plot:**
* **X-axis:** Compute (PF-days), excluding embeddings. Logarithmic scale from approximately 10^-7 to 10^-1.
* **Y-axis:** Steps. Linear scale from 0 to 15000.
* **Data Series 1 (Blue):** `S_min (adjusted)` (solid line with circular markers)
* **Data Series 2 (Blue):** `S_min = (5.4 * 10^3) * C_min^0.03` (dashed line)
* **Data Series 3 (Orange):** `S (fixed-batch)` (solid line with circular markers)
### Detailed Analysis
**Left Plot (Parameters vs. Compute):**
* **Blue Data Series:** The blue dashed line represents the equation `N = (1.3 * 10^9) * C_min^0.73`. The data points cluster closely around this line, indicating a strong relationship between compute and the number of parameters. As compute increases, the number of parameters also increases.
* At Compute = 10^-7, Parameters ≈ 2000
* At Compute = 10^-1, Parameters ≈ 5 * 10^6
* **Orange Data Series:** The orange dashed line represents the equation `N = (1.6 * 10^9) * C_min^0.88`. The data points cluster closely around this line, indicating a strong relationship between compute and the number of parameters. As compute increases, the number of parameters also increases. The orange line is generally below the blue line.
* At Compute = 10^-7, Parameters ≈ 1000
* At Compute = 10^-1, Parameters ≈ 3 * 10^6
**Right Plot (Steps vs. Compute):**
* **Blue Data Series (Adjusted):** The blue solid line with circular markers represents `S_min (adjusted)`. The number of steps increases slightly with compute, but the relationship is not as clear as in the left plot. There is more variance in the data.
* At Compute = 10^-7, Steps ≈ 2000
* At Compute = 10^-3, Steps ≈ 4000
* At Compute = 10^-2, Steps ≈ 3000
* At Compute = 10^-1, Steps ≈ 4000
* **Blue Data Series (Equation):** The blue dashed line represents the equation `S_min = (5.4 * 10^3) * C_min^0.03`. This line provides a smoothed representation of the relationship between compute and steps.
* At Compute = 10^-7, Steps ≈ 3000
* At Compute = 10^-1, Steps ≈ 3500
* **Orange Data Series (Fixed-Batch):** The orange solid line with circular markers represents `S (fixed-batch)`. The number of steps increases significantly with compute, especially at higher compute values. The relationship is more pronounced than the adjusted steps.
* At Compute = 10^-7, Steps ≈ 2000
* At Compute = 10^-3, Steps ≈ 3000
* At Compute = 10^-2, Steps ≈ 5000
* At Compute = 10^-1, Steps ≈ 15000
### Key Observations
* The left plot shows a strong positive correlation between compute and the number of parameters.
* The right plot shows a weaker correlation between compute and the number of steps, especially for the adjusted steps. The fixed-batch steps show a more pronounced increase with compute.
* The equations provided in the legends appear to be fitted models representing the relationships between the variables.
### Interpretation
The plots suggest that increasing compute leads to a significant increase in the number of parameters in the non-embedding layers of the model. The relationship between compute and the number of steps is more complex. The adjusted steps show a relatively flat trend, while the fixed-batch steps show a more significant increase with compute, suggesting that the batch size influences the number of steps required. The difference between the adjusted and fixed-batch steps could be due to different optimization strategies or hyperparameter settings. The equations provided offer a quantitative way to estimate the number of parameters or steps given a certain amount of compute.