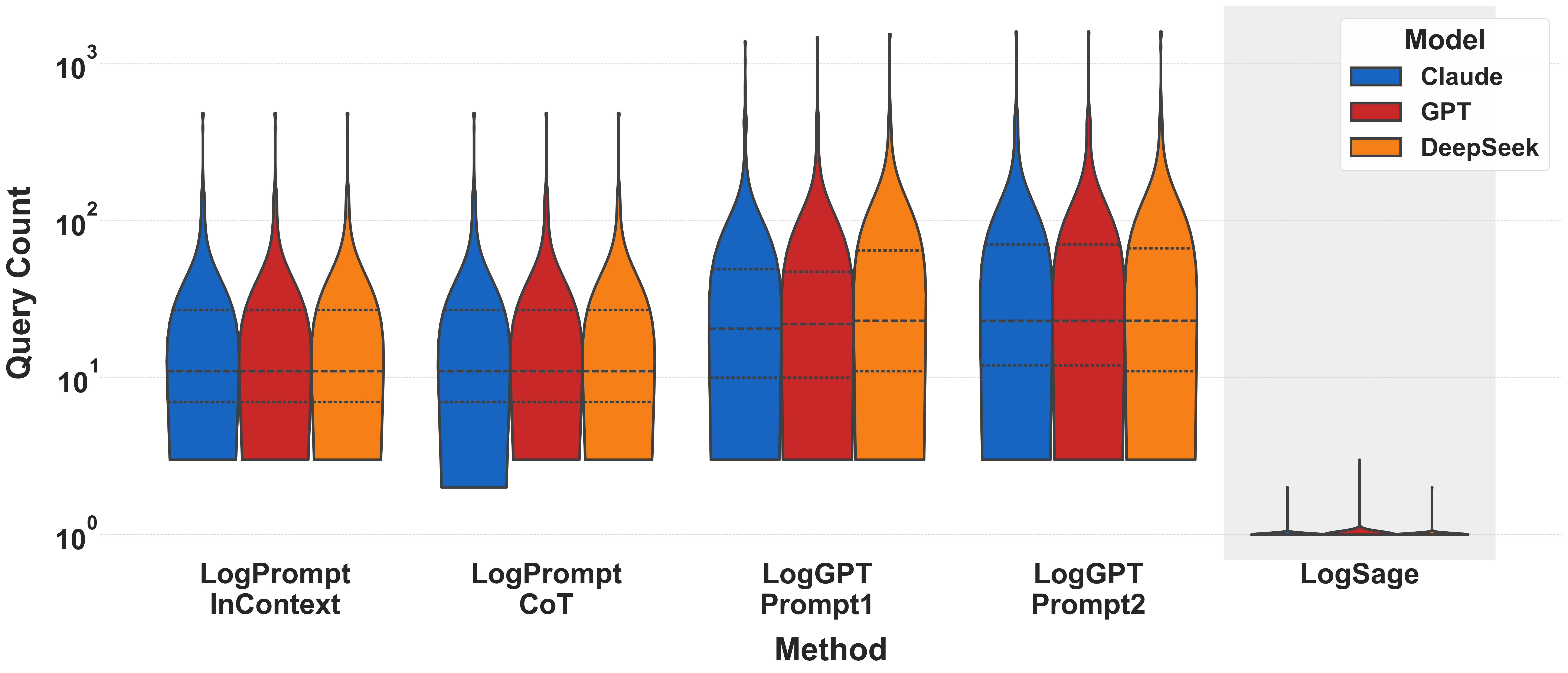
# Technical Document Extraction: Violin Plot Analysis
## Axis Labels and Titles
- **X-Axis**:
- Title: `Method`
- Categories:
1. `LogPrompt InContext`
2. `LogPrompt CoT`
3. `LogGPT Prompt1`
4. `LogGPT Prompt2`
5. `LogSage`
- **Y-Axis**:
- Title: `Query Count`
- Scale: Logarithmic (10⁰ to 10³)
- Tick Marks: 10⁰, 10¹, 10², 10³
## Legend
- **Models**:
- Blue: `Claude`
- Red: `GPT`
- Orange: `DeepSeek`
## Violin Plot Components
- **Structure**:
- Each violin represents the distribution of query counts for a specific method and model.
- Dashed horizontal lines within violins indicate quartiles (Q1, median, Q3).
- Vertical black lines at the top represent maximum values.
- **Key Observations**:
1. **LogPrompt InContext**:
- All models show similar distributions, with medians clustered near 10¹.
- Maximum values (~10²) are comparable across models.
2. **LogPrompt CoT**:
- `Claude` exhibits a narrower distribution (lower variance) compared to `GPT` and `DeepSeek`.
- `GPT` and `DeepSeek` show higher median values (~10¹.⁵) and extended upper ranges.
3. **LogGPT Prompt1/Prompt2**:
- `GPT` and `DeepSeek` demonstrate significantly higher query counts (medians ~10²).
- `Claude` remains relatively low (median ~10¹).
- `LogGPT Prompt2` has the highest maximum values (~10³) for all models.
4. **LogSage (Inset)**:
- A narrow spike at ~10⁰ for all models, indicating minimal query counts.
- `GPT` shows a slightly broader distribution than `Claude` and `DeepSeek`.
## Inset Details
- **LogSage**:
- Y-Axis: `Query Count` (log scale, 10⁰ to 10¹)
- X-Axis: `Model` (Claude, GPT, DeepSeek)
- Key Feature: Sharp spike at ~10⁰ for all models, suggesting near-zero query counts.
## Cross-Referenced Data Points
| Method | Model | Median (Approx.) | Max (Approx.) |
|----------------------|---------|------------------|---------------|
| LogPrompt InContext | Claude | 10¹ | 10² |
| LogPrompt InContext | GPT | 10¹ | 10² |
| LogPrompt InContext | DeepSeek| 10¹ | 10² |
| LogPrompt CoT | Claude | 10¹ | 10¹.⁵ |
| LogPrompt CoT | GPT | 10¹.⁵ | 10² |
| LogPrompt CoT | DeepSeek| 10¹.⁵ | 10² |
| LogGPT Prompt1 | Claude | 10¹ | 10² |
| LogGPT Prompt1 | GPT | 10² | 10³ |
| LogGPT Prompt1 | DeepSeek| 10² | 10³ |
| LogGPT Prompt2 | Claude | 10¹ | 10² |
| LogGPT Prompt2 | GPT | 10² | 10³ |
| LogGPT Prompt2 | DeepSeek| 10² | 10³ |
## Notes
- **Log Scale Implications**:
- Exponential growth in query counts is visually compressed, emphasizing relative differences.
- Outliers (e.g., LogGPT Prompt2) are more pronounced due to the logarithmic scale.
- **Model Performance**:
- `GPT` and `DeepSeek` consistently show higher query counts than `Claude` across most methods.
- `LogGPT Prompt2` amplifies this trend, with `GPT` and `DeepSeek` reaching ~10³ queries.
- **LogSage Anomaly**:
- The inset suggests `LogSage` is either highly efficient (low query counts) or underutilized compared to other methods.