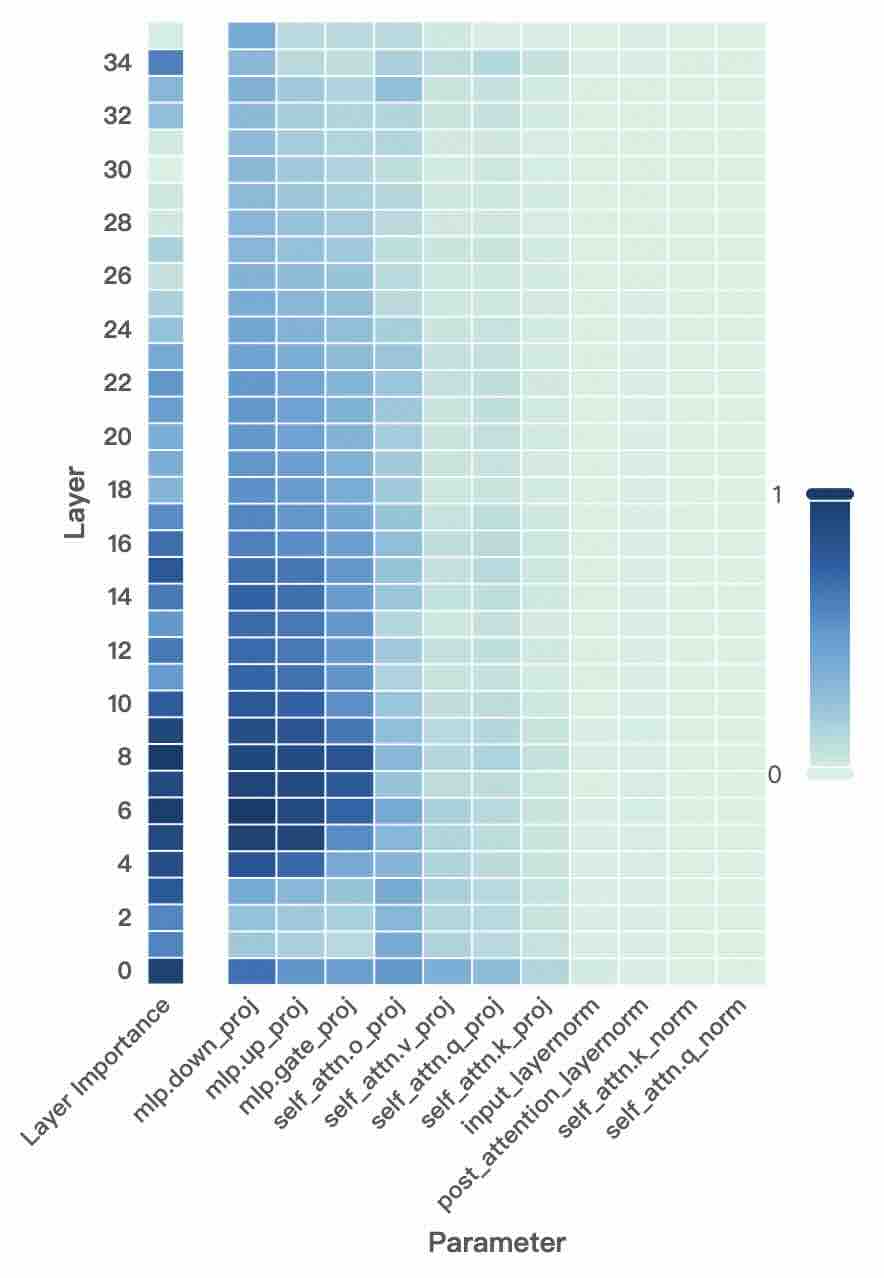
## Heatmap: Layer Importance vs. Parameter
### Overview
This image presents a heatmap visualizing the relationship between layer number and the importance of various parameters within a neural network model. The heatmap uses a color gradient to represent the magnitude of importance, ranging from 0 (light color) to 1 (dark color). The x-axis represents different parameters, and the y-axis represents the layer number.
### Components/Axes
* **X-axis:** Parameter. The parameters listed are: `mlp.down_proj`, `mlp.up_proj`, `mlp.gate_proj`, `self_attn.o_proj`, `self_attn.v_proj`, `self_attn.q_proj`, `self_attn.k_proj`, `input_layernorm`, `post_attention_layernorm`, `self_attn.k_norm`, `self_attn.q_norm`.
* **Y-axis:** Layer. The layer numbers range from 0 to 34, with increments of 2.
* **Color Scale:** A continuous color gradient is used, with 0 represented by a light color (almost white) and 1 represented by a dark blue. The scale is positioned on the right side of the heatmap.
* **Title:** Not explicitly present, but the chart represents "Layer Importance vs. Parameter".
### Detailed Analysis
The heatmap displays a grid of colored cells, each representing the importance score for a specific parameter at a specific layer.
* **mlp.down_proj:** Shows high importance (dark blue) for layers 0-12, then gradually decreases to near 0 for layers above 12.
* **mlp.up_proj:** Similar to `mlp.down_proj`, high importance for layers 0-12, decreasing to near 0 above 12.
* **mlp.gate_proj:** High importance for layers 0-10, decreasing to near 0 above 10.
* **self_attn.o_proj:** Shows moderate importance (medium blue) across layers 0-20, then decreases to near 0.
* **self_attn.v_proj:** Moderate importance across layers 0-20, then decreases to near 0.
* **self_attn.q_proj:** Moderate importance across layers 0-20, then decreases to near 0.
* **self_attn.k_proj:** Moderate importance across layers 0-20, then decreases to near 0.
* **input_layernorm:** Shows low to moderate importance (light to medium blue) across all layers, with a slight increase in the middle layers (8-20).
* **post_attention_layernorm:** Shows low to moderate importance (light to medium blue) across all layers, with a slight increase in the middle layers (8-20).
* **self_attn.k_norm:** Shows low importance (very light blue) across all layers.
* **self_attn.q_norm:** Shows low importance (very light blue) across all layers.
**Approximate Values (based on visual estimation):**
| Parameter | Layer 0 | Layer 8 | Layer 16 | Layer 24 | Layer 32 |
| ---------------------- | ------- | ------- | -------- | -------- | -------- |
| mlp.down_proj | ~0.9 | ~0.7 | ~0.3 | ~0.1 | ~0.0 |
| mlp.up_proj | ~0.9 | ~0.7 | ~0.3 | ~0.1 | ~0.0 |
| mlp.gate_proj | ~0.8 | ~0.6 | ~0.2 | ~0.0 | ~0.0 |
| self_attn.o_proj | ~0.5 | ~0.4 | ~0.2 | ~0.1 | ~0.0 |
| self_attn.v_proj | ~0.5 | ~0.4 | ~0.2 | ~0.1 | ~0.0 |
| self_attn.q_proj | ~0.5 | ~0.4 | ~0.2 | ~0.1 | ~0.0 |
| self_attn.k_proj | ~0.5 | ~0.4 | ~0.2 | ~0.1 | ~0.0 |
| input_layernorm | ~0.2 | ~0.3 | ~0.2 | ~0.2 | ~0.1 |
| post_attention_layernorm | ~0.2 | ~0.3 | ~0.2 | ~0.2 | ~0.1 |
| self_attn.k_norm | ~0.0 | ~0.0 | ~0.0 | ~0.0 | ~0.0 |
| self_attn.q_norm | ~0.0 | ~0.0 | ~0.0 | ~0.0 | ~0.0 |
### Key Observations
* The `mlp` parameters (`mlp.down_proj`, `mlp.up_proj`, `mlp.gate_proj`) exhibit the highest importance in the earlier layers (0-12) and rapidly decrease in importance as the layer number increases.
* The `self_attn` parameters (`self_attn.o_proj`, `self_attn.v_proj`, `self_attn.q_proj`, `self_attn.k_proj`) show moderate importance in the initial layers, also decreasing with layer depth.
* The `input_layernorm` and `post_attention_layernorm` parameters have relatively consistent, low-to-moderate importance across all layers.
* The `self_attn.k_norm` and `self_attn.q_norm` parameters consistently show very low importance across all layers.
### Interpretation
This heatmap suggests that the `mlp` and `self_attn` components are most crucial in the initial layers of the neural network. As the data propagates through deeper layers, their influence diminishes. The normalization layers (`input_layernorm` and `post_attention_layernorm`) provide a consistent, but less pronounced, contribution across all layers, likely stabilizing the learning process. The very low importance of `self_attn.k_norm` and `self_attn.q_norm` might indicate that these normalization steps are less critical for the model's performance or that their effect is already captured by other components.
The decreasing importance of the `mlp` and `self_attn` parameters with increasing layer depth could indicate that the model is learning to extract more abstract and high-level features in the later layers, relying less on the initial parameter transformations. This is a common pattern in deep learning models, where early layers often focus on low-level feature extraction, and later layers combine these features to form more complex representations. The heatmap provides a visual representation of this hierarchical feature learning process.