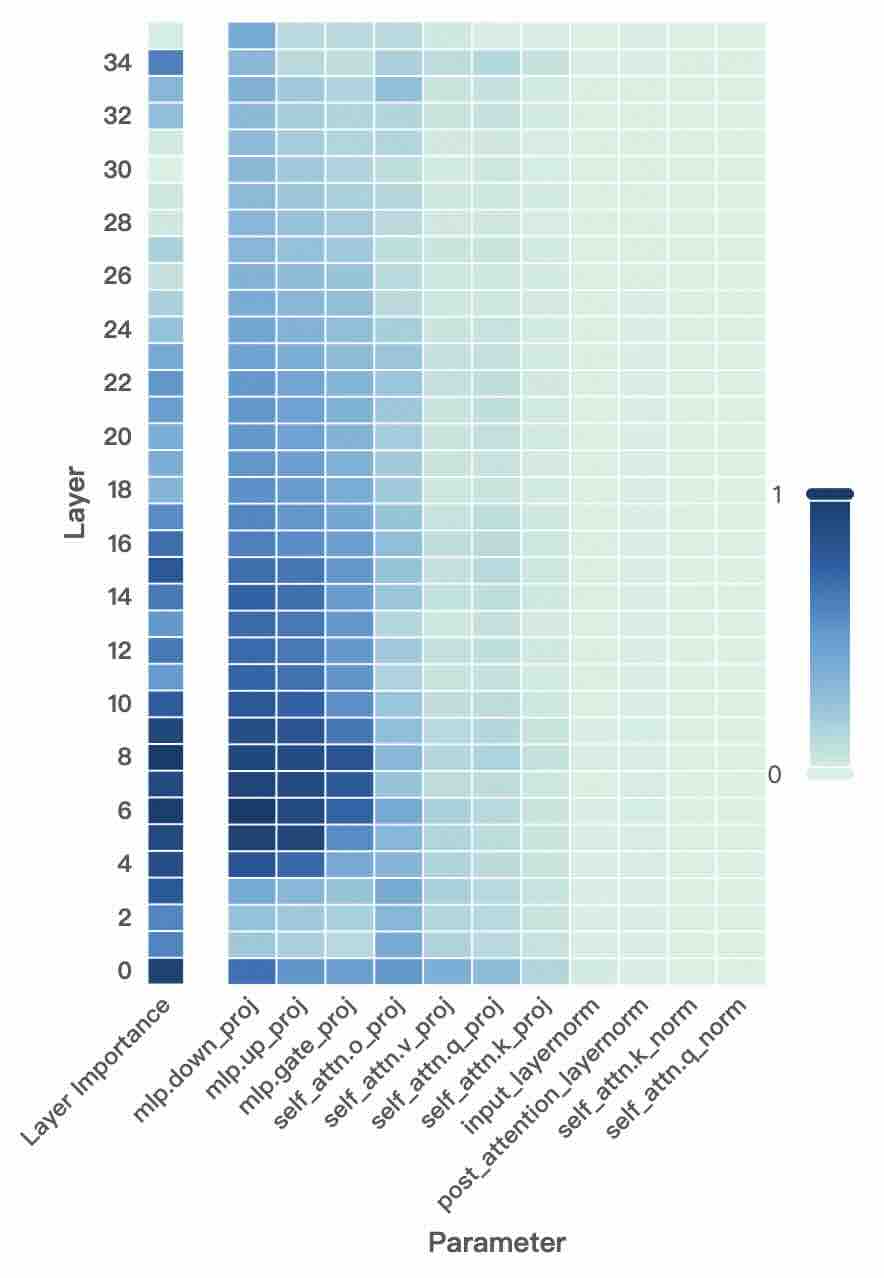
## Heatmap: Parameter Importance Across Transformer Layers
### Overview
This heatmap visualizes the importance scores of various parameters across 35 transformer layers (0-34). Darker blue indicates higher importance (closer to 1), while lighter blue indicates lower importance (closer to 0). The parameters analyzed include MLP projections, attention mechanisms, and layer normalization components.
### Components/Axes
- **Y-axis (Layer)**: Layer numbers from 0 (bottom) to 34 (top), increasing upward.
- **X-axis (Parameter)**:
- `Layer Importance` (baseline)
- `mlp.down_proj`, `mlp.up_proj`, `mlp.gate_proj`, `mlp.attn.o_proj`, `mlp.attn.v_proj`, `mlp.attn.q_proj`
- `self_attn.o_proj`, `self_attn.q_proj`, `self_attn.k_proj`
- `input_layernorm`, `post_attention_layernorm`, `self_attn.k_norm`, `self_attn.q_norm`
- **Color Scale**: Right-side bar from 0 (lightest) to 1 (darkest).
### Detailed Analysis
1. **MLP Parameters**:
- `mlp.down_proj` (darkest blue) shows highest importance in early layers (0-8), peaking at ~0.9 in layer 0, then declining to ~0.3 by layer 34.
- `mlp.up_proj` follows a similar trend but with slightly lower values (~0.8 in layer 0, ~0.2 in layer 34).
- `mlp.gate_proj` and `mlp.attn.*_proj` parameters show moderate importance in early layers (~0.6-0.7 in layer 0), fading to near-zero in later layers.
2. **Self-Attention Parameters**:
- `self_attn.o_proj` peaks at ~0.7 in layer 10, then declines to ~0.2 by layer 34.
- `self_attn.q_proj` and `self_attn.k_proj` show moderate importance (~0.5-0.6) in layers 8-16, fading afterward.
3. **Normalization Parameters**:
- `input_layernorm` and `post_attention_layernorm` show minimal importance (<0.1) across all layers.
- `self_attn.k_norm` and `self_attn.q_norm` remain consistently low (<0.05) throughout.
### Key Observations
- **Layer-Specific Importance**: MLP parameters dominate early layers (0-8), while self-attention parameters peak in middle layers (8-16). Post-attention parameters show negligible importance.
- **Consistent Decline**: Most parameters exhibit a clear downward trend in importance as layer depth increases.
- **Normalization Insignificance**: Layer normalization components (`input_layernorm`, `post_attention_layernorm`) have uniformly low importance scores.
### Interpretation
The heatmap reveals a hierarchical importance structure in transformer layers:
1. **Early Layers (0-8)**: MLP projections (`mlp.down_proj`, `mlp.up_proj`) drive critical transformations, suggesting these layers handle foundational feature extraction.
2. **Middle Layers (8-16)**: Self-attention mechanisms (`self_attn.o_proj`, `self_attn.q_proj`) become moderately important, indicating their role in feature integration and contextual modeling.
3. **Later Layers (16-34)**: Importance scores drop sharply, with normalization parameters showing near-zero values. This suggests later layers focus on refinement rather than major transformations.
The data implies that transformer architectures prioritize MLP operations in early layers for feature learning, while self-attention mechanisms gain relevance in middle layers for contextual modeling. Post-attention normalization components appear to have minimal impact across all layers, potentially indicating architectural redundancy or optimization opportunities.