## Bar Chart: E-CARE: Avg. Coherence
### Overview
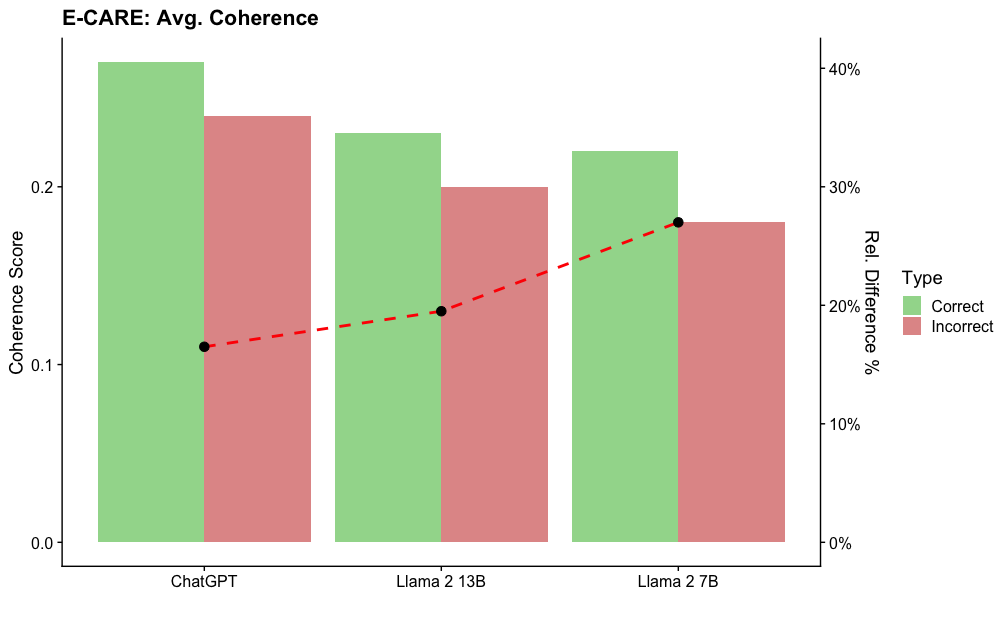
The image is a bar chart comparing the average coherence scores of three language models (ChatGPT, Llama 2 13B, and Llama 2 7B) on the E-CARE dataset. The chart displays coherence scores for both "Correct" and "Incorrect" response types, represented by green and red bars, respectively. A dashed red line plots the relative difference between the "Correct" and "Incorrect" scores.
### Components/Axes
* **Title:** E-CARE: Avg. Coherence
* **X-axis:** Categorical axis with three categories: ChatGPT, Llama 2 13B, Llama 2 7B
* **Left Y-axis:** "Coherence Score" ranging from 0.0 to 0.25, with tick marks at 0.0, 0.1, and 0.2.
* **Right Y-axis:** "Rel. Difference %" ranging from 0% to 40%, with tick marks at 0%, 10%, 20%, 30%, and 40%.
* **Legend:** Located on the right side of the chart, indicating "Correct" responses with a green bar and "Incorrect" responses with a red bar.
* **Data Series:**
* Correct: Green bars representing the coherence score for correct responses.
* Incorrect: Red bars representing the coherence score for incorrect responses.
* Relative Difference: Dashed red line representing the relative difference between correct and incorrect scores.
### Detailed Analysis
**ChatGPT:**
* Correct (Green): Approximately 0.25
* Incorrect (Red): Approximately 0.23
* Relative Difference (Red Dashed Line): Approximately 11%
**Llama 2 13B:**
* Correct (Green): Approximately 0.23
* Incorrect (Red): Approximately 0.20
* Relative Difference (Red Dashed Line): Approximately 21%
**Llama 2 7B:**
* Correct (Green): Approximately 0.22
* Incorrect (Red): Approximately 0.18
* Relative Difference (Red Dashed Line): Approximately 28%
### Key Observations
* The "Correct" coherence scores are consistently higher than the "Incorrect" coherence scores for all three models.
* The relative difference between "Correct" and "Incorrect" scores increases from ChatGPT to Llama 2 13B to Llama 2 7B.
* ChatGPT has the highest "Correct" coherence score, while Llama 2 7B has the lowest.
### Interpretation
The chart suggests that all three language models exhibit higher coherence in their "Correct" responses compared to their "Incorrect" responses. The increasing relative difference from ChatGPT to Llama 2 7B indicates that the gap in coherence between correct and incorrect responses widens for the Llama 2 models, especially the 7B version. This could imply that the Llama 2 models are more sensitive to the quality of input or context, leading to a greater disparity in coherence when generating incorrect responses. ChatGPT, on the other hand, maintains a relatively smaller difference, suggesting a more consistent level of coherence regardless of response correctness.