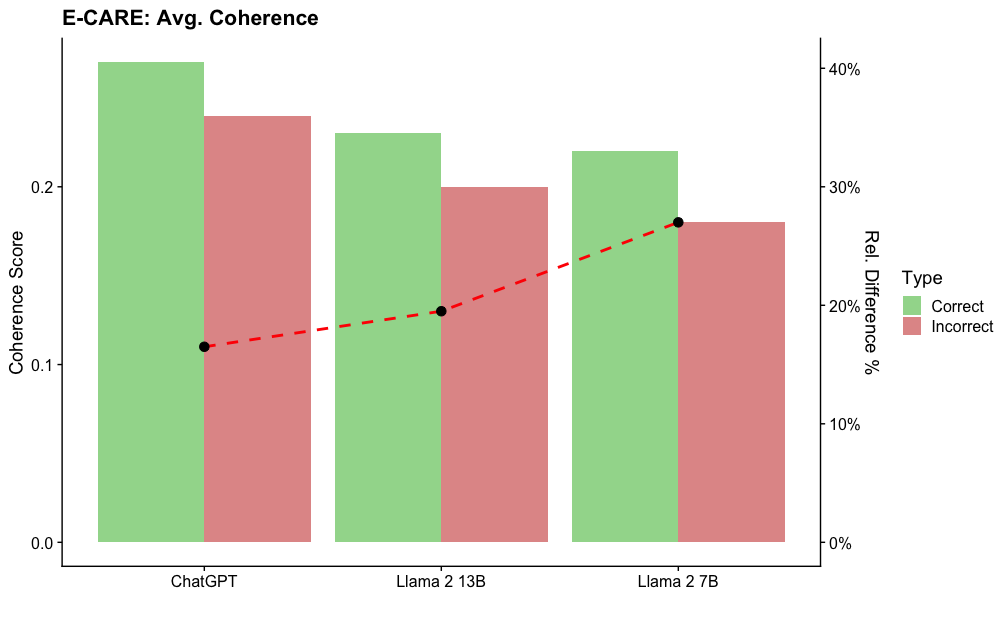
## Bar Chart: E-CARE: Avg. Coherence
### Overview
The chart compares average coherence scores for three language models (ChatGPT, Llama 2 13B, Llama 2 7B) across two categories: "Correct" (green) and "Incorrect" (red) responses. A red dashed line labeled "Rel. Difference %" overlays the chart, showing a trend from 0% to 40%.
### Components/Axes
- **X-axis**: Model names (ChatGPT, Llama 2 13B, Llama 2 7B), evenly spaced.
- **Y-axis (left)**: Coherence Score (0.0–0.4), linear scale.
- **Legend**:
- Green = "Correct" responses
- Red = "Incorrect" responses
- **Secondary Y-axis (right)**: "Rel. Difference %" (0%–40%), aligned with the red dashed line.
### Detailed Analysis
1. **ChatGPT**:
- Correct: ~0.38
- Incorrect: ~0.28
- Red dashed line: 0% (bottom of the chart).
2. **Llama 2 13B**:
- Correct: ~0.25
- Incorrect: ~0.20
- Red dashed line: ~15%.
3. **Llama 2 7B**:
- Correct: ~0.23
- Incorrect: ~0.18
- Red dashed line: ~25%.
### Key Observations
- **Coherence Scores**: ChatGPT outperforms both Llama models in both "Correct" and "Incorrect" categories.
- **Relative Difference**: The red dashed line increases from ChatGPT to Llama 2 7B, suggesting a growing disparity between correct and incorrect coherence scores as model size decreases.
- **Bar Heights**: All "Correct" bars exceed "Incorrect" bars, but the gap narrows for smaller models (Llama 2 7B).
### Interpretation
The data suggests that larger models (e.g., ChatGPT) maintain higher coherence scores overall, with a smaller relative gap between correct and incorrect responses. Smaller models (e.g., Llama 2 7B) show reduced coherence, with a larger relative difference between correct and incorrect scores. The red dashed line ("Rel. Difference %") visually reinforces this trend, though its exact calculation (e.g., percentage difference relative to total, incorrect, or another metric) is not explicitly defined in the chart. This could imply that model size impacts not only absolute coherence but also the consistency of responses across correctness categories.