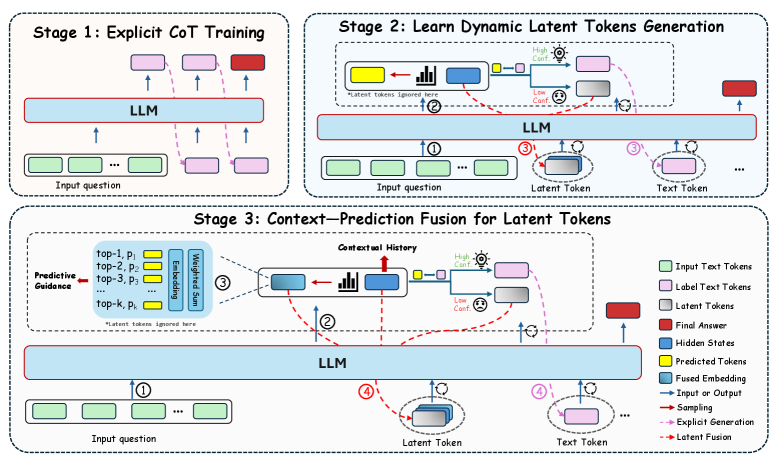
## Diagram: Multi-Stage Training Process for LLMs with Latent Tokens
### Overview
The image presents a three-stage training process for Large Language Models (LLMs), focusing on incorporating latent tokens. The stages are: 1) Explicit Chain-of-Thought (CoT) Training, 2) Learning Dynamic Latent Token Generation, and 3) Context-Prediction Fusion for Latent Tokens. The diagram illustrates the flow of information and the interaction between different components within each stage.
### Components/Axes
* **Stages:** The diagram is divided into three distinct stages, each enclosed in a rounded-corner rectangle.
* **LLM:** A central "LLM" block represents the Large Language Model. It's a light blue rectangle.
* **Input Question:** Represented by green rounded rectangles.
* **Label Text Tokens:** Represented by light pink rounded rectangles.
* **Latent Tokens:** Represented by gray rounded rectangles.
* **Final Answer:** Represented by a red rounded rectangle.
* **Hidden States:** Not explicitly shown as shapes, but implied within the LLM.
* **Predicted Tokens:** Represented by yellow rounded rectangles.
* **Fused Embedding:** Represented by blue rounded rectangles with a bar chart inside.
* **Arrows:** Different types of arrows indicate the flow of information:
* Solid blue arrows: Input or Output
* Solid red arrows: Sampling
* Dashed pink arrows: Explicit Generation
* Dashed brown arrows: Latent Fusion
* **Legend:** Located in the bottom-right corner, explaining the different shapes and arrow types.
### Detailed Analysis
**Stage 1: Explicit CoT Training**
* **Description:** This stage focuses on training the LLM with explicit Chain-of-Thought reasoning.
* **Flow:**
1. An "Input question" (green) is fed into the "LLM".
2. The LLM generates "Label Text Tokens" (pink) in a chain-of-thought manner.
3. The final output is the "Final Answer" (red).
* The arrows are solid blue (Input/Output) and dashed pink (Explicit Generation).
**Stage 2: Learn Dynamic Latent Tokens Generation**
* **Description:** This stage focuses on generating dynamic latent tokens.
* **Flow:**
1. An "Input question" (green) is fed into the "LLM" (blue arrow labeled "1").
2. The LLM generates a "Fused Embedding" (blue rectangle with a bar chart inside).
3. The "Fused Embedding" is used to generate "Predicted Tokens" (yellow).
4. The "Predicted Tokens" are used to generate "Latent Tokens" (gray) (dashed brown arrow labeled "2").
5. The "Latent Tokens" and "Text Tokens" are fed back into the "LLM" (blue arrows labeled "3").
6. The LLM generates the "Final Answer" (red).
* **Additional Elements:**
* "Latent tokens ignored here" is written below the "Predicted Tokens" and "Fused Embedding".
* "High Conf." and "Low Conf." icons are present near the "Predicted Tokens" and "Latent Tokens" respectively.
**Stage 3: Context-Prediction Fusion for Latent Tokens**
* **Description:** This stage focuses on fusing context and prediction to generate latent tokens.
* **Flow:**
1. An "Input question" (green) is fed into the "LLM" (blue arrow labeled "1").
2. "Predictive Guidance" is provided, consisting of "top-1, p1", "top-2, p2", "top-3, p3", ..., "top-k, pk" (blue box).
3. These are processed through "Embedding" and "Weighted Sum" to create a "Fused Embedding" (blue rectangle with a bar chart inside).
4. The "Fused Embedding" is used to generate "Predicted Tokens" (yellow).
5. The "Predicted Tokens" are used to generate "Latent Tokens" (gray) (dashed brown arrow labeled "2").
6. The "Latent Tokens" and "Text Tokens" are fed back into the "LLM" (blue arrows labeled "4").
7. The LLM generates the "Final Answer" (red).
* **Additional Elements:**
* "Contextual History" is indicated above the "Fused Embedding".
* "Latent tokens ignored here" is written below the "Predictive Guidance" box.
* "High Conf." and "Low Conf." icons are present near the "Predicted Tokens" and "Latent Tokens" respectively.
### Key Observations
* The diagram illustrates a progressive training process, starting with explicit CoT training and moving towards incorporating latent tokens.
* Stages 2 and 3 introduce the concept of "Latent Tokens" and their generation through "Predicted Tokens" and "Fused Embedding".
* Stage 3 incorporates "Predictive Guidance" to influence the generation of "Latent Tokens".
* The "High Conf." and "Low Conf." icons suggest a mechanism for evaluating the confidence of the generated tokens.
### Interpretation
The diagram outlines a sophisticated approach to training LLMs by integrating latent tokens. The progression from explicit CoT training to context-prediction fusion suggests an attempt to enhance the model's reasoning capabilities by leveraging both explicit and implicit information. The use of "Predictive Guidance" in Stage 3 indicates an effort to control and refine the generation of latent tokens, potentially leading to more accurate and relevant outputs. The confidence indicators ("High Conf." and "Low Conf.") likely play a role in filtering or weighting the generated tokens, ensuring that only the most reliable information is used in the final prediction. This multi-stage approach aims to improve the LLM's ability to understand and respond to complex queries by incorporating a richer representation of the input and its context.