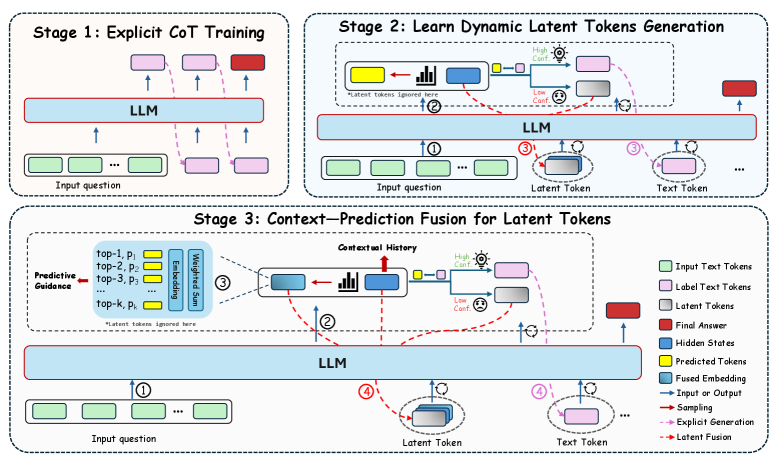
\n
## Diagram: LLM Training Stages
### Overview
The image depicts a three-stage process for training a Large Language Model (LLM), focusing on incorporating dynamic latent tokens to improve performance. The stages are: Explicit Chain-of-Thought (CoT) Training, Learning Dynamic Latent Tokens Generation, and Context-Prediction Fusion for Latent Tokens. The diagram uses a flowchart-like structure with LLM blocks, input/output tokens, and arrows indicating data flow.
### Components/Axes
The diagram is segmented into three stages, each with its own LLM block and associated input/output elements. A legend in the bottom-right corner defines the color-coding for different token types and process indicators.
**Legend:**
* **Input Text Tokens:** Light Green
* **Label Text Tokens:** Pink
* **Latent Tokens:** Red
* **Final Answer:** Dark Blue
* **Hidden States:** Light Blue
* **Predicted Tokens:** Yellow
* **Fused Embedding:** Teal
* **Input or Output:** Black
* **Sampling:** Orange
* **Explicit Generation:** Purple
* **Late Fusion:** Brown
Each stage has an "Input question" block (light green) and an LLM block (light blue). Arrows indicate the flow of information. Stage 3 includes additional components like "Predictive Guidance" (top-1, p1, top-2, p2, top-3, p3), "Embedding", "Weighted Sum", and "Contextual History".
### Detailed Analysis or Content Details
**Stage 1: Explicit CoT Training**
* An "Input question" block (light green) feeds into an LLM block (light blue).
* The LLM outputs "Label Text Tokens" (pink) which are fed back into the LLM.
* Arrows indicate a cyclical process within the LLM.
**Stage 2: Learn Dynamic Latent Tokens Generation**
* An "Input question" block (light green) feeds into an LLM block (light blue).
* The LLM generates "Latent Tokens" (red). A small chart is shown with "High Conf." and "Low Conf." labels.
* The "Latent Tokens" are then converted into "Text Tokens" (yellow) and fed back into the LLM.
* A note states "*Latent tokens ignored here*".
* Numbered circles (1, 2, 3) indicate the flow of information.
**Stage 3: Context-Prediction Fusion for Latent Tokens**
* An "Input question" block (light green) feeds into a "Predictive Guidance" block (containing top-1, p1, top-2, p2, top-3, p3).
* The "Predictive Guidance" block feeds into an "Embedding" block, then a "Weighted Sum" block, and finally into a "Contextual History" block.
* The "Contextual History" block feeds into an LLM block (light blue).
* The LLM generates "Latent Tokens" (red). A small chart is shown with "High Conf." and "Low Conf." labels.
* The "Latent Tokens" are then converted into "Text Tokens" (yellow) and fed back into the LLM.
* A note states "*Latent tokens ignored here*".
* Numbered circles (1, 2, 3, 4) indicate the flow of information.
* Arrows indicate the flow of information, including "Sampling" (orange), "Explicit Generation" (purple), and "Late Fusion" (brown).
### Key Observations
The diagram highlights a progressive refinement of the LLM's ability to generate and utilize latent tokens. Stage 1 establishes a baseline through explicit CoT training. Stage 2 introduces the generation of latent tokens, while Stage 3 focuses on fusing contextual information with predicted latent tokens to improve accuracy and relevance. The inclusion of confidence levels ("High Conf." and "Low Conf.") suggests a mechanism for evaluating the quality of generated latent tokens.
### Interpretation
This diagram illustrates a sophisticated approach to LLM training that moves beyond simple input-output mapping. By introducing latent tokens, the model can represent and manipulate abstract concepts, potentially leading to more nuanced and accurate responses. The three stages represent a gradual increase in complexity, starting with explicit training, then moving to dynamic token generation, and finally incorporating contextual fusion. The use of predictive guidance and weighted sums suggests an attempt to balance exploration (sampling) with exploitation (predictive accuracy). The "Late Fusion" step indicates a strategy for integrating the latent tokens into the final output, potentially improving coherence and relevance. The diagram suggests a focus on improving the LLM's ability to reason and generate more human-like responses by leveraging the power of latent representations. The notes about ignoring latent tokens in certain steps suggest these are areas for future research or optimization.