# Technical Document Extraction: LLM-Based Latent Token Generation Framework
## Diagram Overview
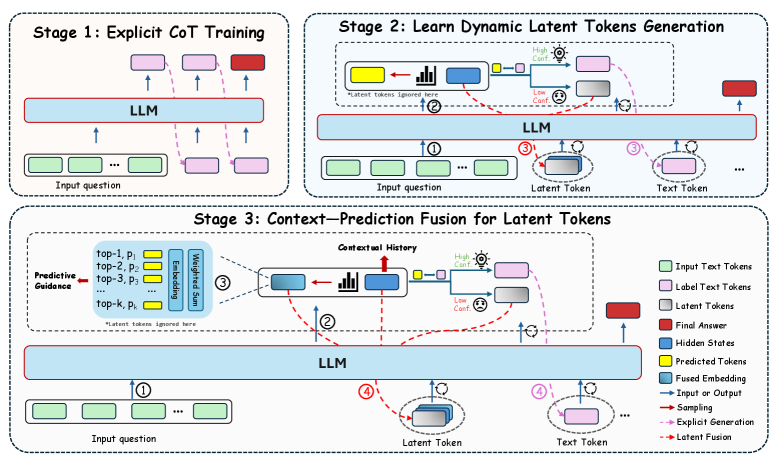
The image depicts a three-stage framework for Latent Token Generation (LTG) using Large Language Models (LLMs). The diagram uses color-coded components and directional arrows to represent data flow and processing stages.
---
## Stage 1: Explicit Chain-of-Thought (CoT) Training
### Components:
1. **Input Question** (Green rectangles)
- Position: Bottom-left of the stage
- Flow: Arrows point upward to the LLM
2. **LLM** (Blue horizontal bar)
- Position: Central horizontal bar
- Function: Processes input tokens
3. **Label Text Tokens** (Pink rectangles)
- Position: Right side of the LLM
- Flow: Arrows connect to the LLM output
4. **Final Answer** (Red rectangle)
- Position: Top-right corner
- Connection: Dashed arrow from LLM output
### Legend Cross-Reference:
- Green = Input Text Tokens
- Pink = Label Text Tokens
- Red = Final Answer
---
## Stage 2: Learn Dynamic Latent Tokens Generation
### Components:
1. **Input Question** (Green rectangles)
- Position: Bottom-left
- Flow: Arrows point to LLM and Latent Token Generator
2. **LLM** (Blue horizontal bar)
- Position: Central
- Function: Processes input tokens
3. **Latent Token Generator** (Yellow/Blue blocks)
- Position: Right of LLM
- Sub-components:
- High Confidence (Yellow)
- Low Confidence (Blue)
4. **Text Token** (Gray rectangles)
- Position: Right of Latent Token Generator
- Flow: Arrows connect to LLM output
5. **Predicted Tokens** (Yellow rectangles)
- Position: Top-right
- Connection: Dashed arrow from Latent Token Generator
### Legend Cross-Reference:
- Blue = Hidden States
- Yellow = Predicted Tokens
- Red Dashed = Latent Fusion
---
## Stage 3: Context-Prediction Fusion for Latent Tokens
### Components:
1. **Input Question** (Green rectangles)
- Position: Bottom-left
- Flow: Arrows point to Predictive Guidance
2. **Predictive Guidance** (Blue blocks)
- Position: Left of LLM
- Sub-components:
- Top-k Predictions (Yellow)
- Embedding Sum (Blue)
3. **Contextual History** (Blue bar)
- Position: Center-left
- Function: Aggregates historical data
4. **LLM** (Blue horizontal bar)
- Position: Central
- Function: Processes fused inputs
5. **Latent Token** (Gray rectangles)
- Position: Right of LLM
- Flow: Arrows connect to Text Token
6. **Text Token** (Gray rectangles)
- Position: Right of Latent Token
- Flow: Arrows connect to Final Answer
7. **Final Answer** (Red rectangle)
- Position: Top-right
- Connection: Dashed arrow from LLM output
### Legend Cross-Reference:
- Blue = Fused Embedding
- Yellow = Predicted Tokens
- Gray = Latent Tokens
- Red = Final Answer
---
## Legend Analysis
- **Color-Coding**:
- Green: Input Text Tokens
- Pink: Label Text Tokens
- Red: Final Answer
- Blue: Hidden States / Fused Embedding
- Yellow: Predicted Tokens / Embedding Sum
- Gray: Latent Tokens / Text Tokens
- Dashed Red: Latent Fusion
- **Spatial Grounding**:
- Legend located on the right side of the diagram
- Color consistency verified across all stages
---
## Key Trends and Flow Analysis
1. **Stage 1** establishes explicit CoT training by connecting input questions to labeled outputs via the LLM.
2. **Stage 2** introduces dynamic latent token generation, splitting predictions into high/low confidence categories.
3. **Stage 3** fuses contextual history with predictive guidance to refine latent tokens before final answer generation.
---
## Textual Information Extraction
### Embedded Text in Diagrams:
- Stage 1: "Explicit CoT Training"
- Stage 2: "Learn Dynamic Latent Tokens Generation"
- Stage 3: "Context-Prediction Fusion for Latent Tokens"
- Component Labels:
- "Predictive Guidance"
- "Contextual History"
- "High Confidence"
- "Low Confidence"
- "Latent Token"
- "Text Token"
---
## Conclusion
This framework illustrates a progressive approach to enhancing LLM performance through explicit training, dynamic latent token generation, and context-aware fusion. The color-coded components and directional arrows provide a clear visualization of the data flow and processing stages.