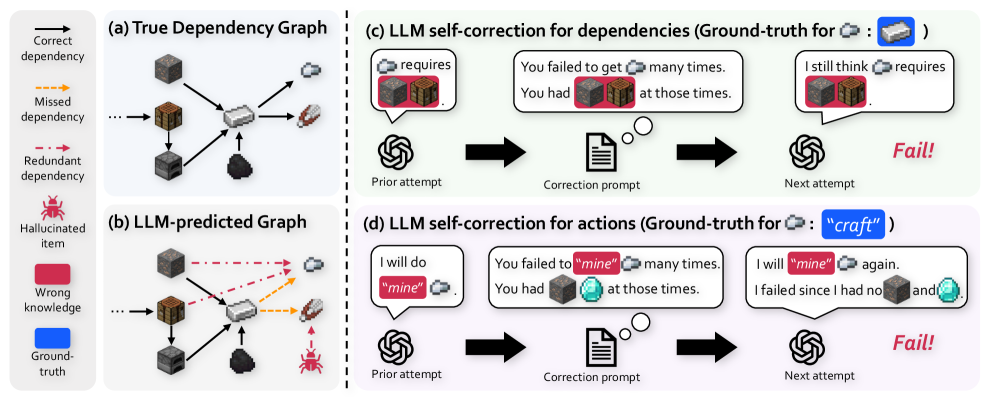
## Diagram: LLM Dependency and Action Correction
### Overview
The image presents a comparative analysis of true dependency graphs versus those predicted by a Large Language Model (LLM), alongside a demonstration of LLM self-correction for both dependencies and actions. It visually contrasts the ideal scenario with the LLM's initial output and subsequent attempts at correction. The diagram is divided into four sections: (a) True Dependency Graph, (b) LLM-predicted Graph, (c) LLM self-correction for dependencies, and (d) LLM self-correction for actions.
### Components/Axes
The diagram utilizes a visual representation of nodes (cubes) and edges (arrows) to depict dependencies and relationships. Each section has a title and a brief description. A legend in section (a) defines the arrow types: solid arrow = "Correct dependency", dashed arrow = "Missed dependency", and dotted arrow = "Redundant dependency". Section (b) introduces "Hallucinated item". Sections (c) and (d) show a sequence of steps: "Prior attempt", "Correction prompt", and "Next attempt", connected by curved arrows. Text boxes within each step display the LLM's generated text. The ground truth for the correction tasks is provided in parentheses after the section titles.
### Detailed Analysis or Content Details
**(a) True Dependency Graph:**
This section shows a network of six interconnected cubes.
* There are six nodes (cubes) arranged in a roughly circular pattern.
* There are seven edges (arrows) representing dependencies.
* All edges are solid, indicating "Correct dependency".
**(b) LLM-predicted Graph:**
This section displays a more complex network of seven nodes (six cubes and one additional item).
* There are seven nodes, including one labeled "Hallucinated item" (a light blue sphere).
* There are nine edges, with a mix of arrow types:
* Five solid arrows ("Correct dependency").
* Two dashed arrows ("Missed dependency").
* Two dotted arrows ("Redundant dependency").
* The "Ground truth" node is connected to the network via a solid arrow.
* The "Wrong knowledge" node is connected to the network via a dashed arrow.
**(c) LLM self-correction for dependencies (Ground-truth for ∷):**
This section illustrates the correction process for dependencies.
* **Prior attempt:** A cube with a texture and a light blue sphere are connected by an arrow labeled "requires". The text reads: "You failed to get ∷ many times. You had ∷ at those times."
* **Correction prompt:** A document icon is shown.
* **Next attempt:** The same cube and sphere are connected by an arrow labeled "requires". The text reads: "I still think ∷ requires". A "Fail!" label is present.
**(d) LLM self-correction for actions (Ground-truth for : "craft"):**
This section demonstrates the correction process for actions.
* **Prior attempt:** A cube with a texture and a light blue sphere are connected. The text reads: "I will do “mine”". The sphere is highlighted in yellow.
* **Correction prompt:** A document icon is shown.
* **Next attempt:** The same cube and sphere are connected. The text reads: "I will “mine” again. I failed since I had no ∷ and". The sphere is highlighted in yellow. A "Fail!" label is present.
### Key Observations
* The LLM-predicted graph (b) exhibits both over- and under-estimation of dependencies compared to the true graph (a). It also introduces a "Hallucinated item" not present in the ground truth.
* The self-correction attempts (c and d) fail to achieve the correct output, despite the correction prompt. The "Fail!" label indicates the LLM did not successfully correct its initial prediction.
* The LLM struggles with both dependency identification and action selection, as demonstrated by the failures in both (c) and (d).
* The use of highlighting (yellow) around "mine" in sections (d) suggests the LLM is focusing on this term during the correction process.
### Interpretation
The diagram highlights the challenges LLMs face in accurately representing and reasoning about dependencies and actions. The LLM's initial prediction contains errors (hallucinations, missed/redundant dependencies), and its self-correction mechanism is insufficient to rectify these errors. This suggests that while LLMs can generate plausible outputs, they lack a robust understanding of the underlying relationships and constraints. The failures in self-correction indicate a need for more sophisticated techniques to improve the reliability and accuracy of LLM-generated knowledge. The use of the symbol ∷ suggests a placeholder or variable that the LLM is attempting to resolve, but consistently fails to do so. The diagram serves as a visual illustration of the gap between LLM capabilities and true reasoning. The consistent "Fail!" label underscores the limitations of the current self-correction approach.