\n
## Diagram: Reward Model Comparison
### Overview
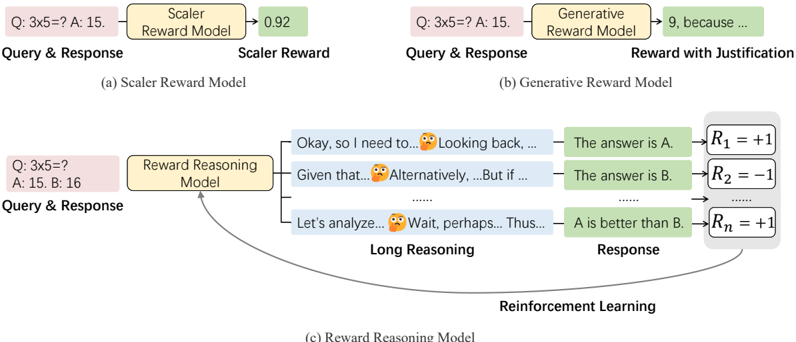
The image is a diagram illustrating three different reward models used in reinforcement learning: a Scalar Reward Model, a Generative Reward Model, and a Reward Reasoning Model. It visually compares how each model processes a query and response to generate a reward signal. The diagram highlights the differences in complexity and the level of justification provided by each model.
### Components/Axes
The diagram is divided into three main sections, labeled (a), (b), and (c), each representing a different reward model. Each section includes:
* **Query & Response:** Represented by an orange box.
* **Reward Model:** Represented by a light green box.
* **Reward Output:** The output of the reward model, varying in format depending on the model type.
* **Reinforcement Learning:** A curved arrow indicating the feedback loop to reinforcement learning.
* **Long Reasoning:** A section in (c) showing intermediate reasoning steps.
### Detailed Analysis or Content Details
**(a) Scalar Reward Model:**
* **Query & Response:** "Q: 3x5=? A: 15."
* **Scalar Reward Model:** Labeled as "Scalar Reward Model".
* **Scalar Reward:** Output is "0.92".
**(b) Generative Reward Model:**
* **Query & Response:** "Q: 3x5=? A: 15."
* **Generative Reward Model:** Labeled as "Generative Reward Model".
* **Reward with Justification:** Output is "9, because ...". The "because..." indicates a textual justification is provided.
**(c) Reward Reasoning Model:**
* **Query & Response:** "Q: 3x5=? A: 15: 16"
* **Reward Reasoning Model:** Labeled as "Reward Reasoning Model".
* **Long Reasoning:** Contains several intermediate reasoning steps represented by green boxes with text:
* "Okay, so I need to..." with a thinking face emoji.
* "Looking back, ..." with a thinking face emoji.
* "Given that..." with a thinking face emoji.
* "Alternatively,...But if..." with a thinking face emoji.
* "Let's analyze..." with a thinking face emoji.
* "Wait, perhaps...Thus..." with a thinking face emoji.
* **Response:** Contains several response options represented by green boxes with text:
* "The answer is A."
* "The answer is B."
* "...".
* **Reinforcement Learning:** A curved arrow connects the "Response" section back to the "Reward Reasoning Model", indicating a feedback loop.
* **Rewards:** Represented by equations:
* R<sub>1</sub> = +1
* R<sub>2</sub> = -1
* R<sub>n</sub> = +1
### Key Observations
* The Scalar Reward Model provides a single numerical reward.
* The Generative Reward Model provides a numerical reward *and* a textual justification.
* The Reward Reasoning Model demonstrates a multi-step reasoning process before arriving at a reward, and provides multiple possible responses with associated rewards.
* The use of emojis in the "Long Reasoning" section suggests a simulation of thought processes.
* The rewards (R1, R2, Rn) are simple binary rewards (+1 or -1), indicating a basic reward structure.
### Interpretation
The diagram illustrates a progression in the complexity of reward models used in reinforcement learning. The Scalar Reward Model is the simplest, offering a direct numerical assessment. The Generative Reward Model adds interpretability by providing a justification for the reward. The Reward Reasoning Model is the most sophisticated, simulating a reasoning process and offering a more nuanced evaluation of the response.
The diagram suggests that more complex reward models can provide richer feedback signals to the reinforcement learning agent, potentially leading to more effective learning. The inclusion of intermediate reasoning steps in the Reward Reasoning Model highlights the importance of explainability and transparency in AI systems. The use of emojis is a stylistic choice to emphasize the "thinking" aspect of the model. The diagram demonstrates a shift from simple reward signals to more human-like reasoning and justification in reward mechanisms.