## Line Chart: Computation Time vs. Sequence Length
### Overview
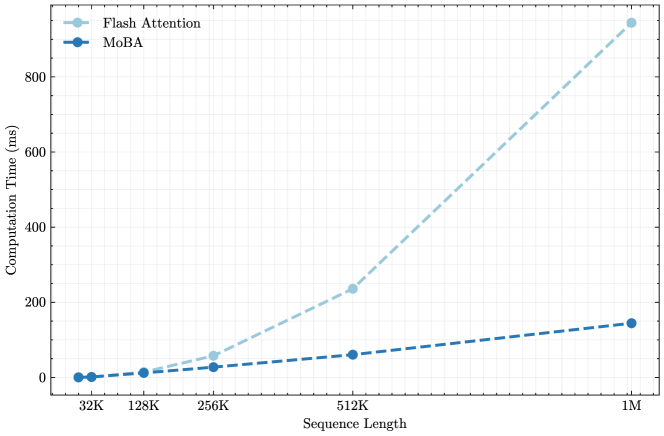
The image is a line chart comparing the computation time (in milliseconds) of "Flash Attention" and "MoBA" algorithms across varying sequence lengths. The x-axis represents the sequence length, while the y-axis represents the computation time.
### Components/Axes
* **X-axis:** Sequence Length, with markers at 32K, 128K, 256K, 512K, and 1M.
* **Y-axis:** Computation Time (ms), with markers at 0, 200, 400, 600, and 800.
* **Legend (top-left):**
* Flash Attention (light blue, dashed line)
* MoBA (dark blue, dashed line)
### Detailed Analysis
* **Flash Attention (light blue, dashed line):** The computation time increases exponentially with the sequence length.
* 32K: ~5 ms
* 128K: ~10 ms
* 256K: ~40 ms
* 512K: ~230 ms
* 1M: ~900 ms
* **MoBA (dark blue, dashed line):** The computation time increases linearly with the sequence length.
* 32K: ~2 ms
* 128K: ~8 ms
* 256K: ~15 ms
* 512K: ~60 ms
* 1M: ~140 ms
### Key Observations
* At shorter sequence lengths (32K to 256K), the computation times for Flash Attention and MoBA are relatively close.
* As the sequence length increases (512K to 1M), the computation time for Flash Attention increases dramatically compared to MoBA.
* MoBA consistently exhibits lower computation times than Flash Attention across all sequence lengths tested.
### Interpretation
The chart demonstrates that MoBA is more computationally efficient than Flash Attention, especially for longer sequence lengths. The exponential increase in computation time for Flash Attention suggests that it may not scale as well as MoBA for large sequence lengths. This information is crucial for selecting the appropriate algorithm based on the expected sequence length and computational resources available. The data suggests that MoBA is a better choice for applications dealing with very long sequences, while Flash Attention might be suitable for shorter sequences where the difference in computation time is less significant.