\n
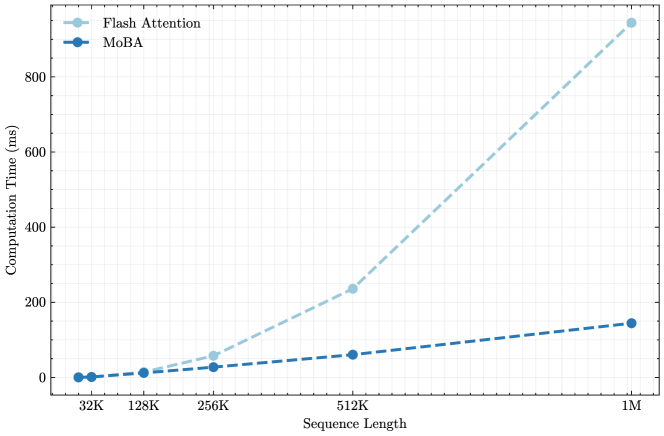
## Line Chart: Computation Time vs. Sequence Length
### Overview
This chart displays the relationship between computation time (in milliseconds) and sequence length for two different methods: Flash Attention and MoBA. The x-axis represents sequence length, and the y-axis represents computation time. The chart shows how computation time scales with increasing sequence length for each method.
### Components/Axes
* **X-axis Title:** Sequence Length
* **Y-axis Title:** Computation Time (ms)
* **X-axis Markers:** 32K, 128K, 256K, 512K, 1M (representing sequence lengths of 32,000, 128,000, 256,000, 512,000, and 1,000,000 respectively)
* **Y-axis Scale:** 0 to 900 ms, with increments of 100 ms.
* **Legend:** Located in the top-left corner.
* **Flash Attention:** Represented by a light blue dashed line with circular markers.
* **MoBA:** Represented by a dark blue solid line with circular markers.
### Detailed Analysis
**Flash Attention (Light Blue Dashed Line):**
The line slopes upward, indicating that computation time increases with sequence length.
* At 32K sequence length: Approximately 0 ms.
* At 128K sequence length: Approximately 10 ms.
* At 256K sequence length: Approximately 60 ms.
* At 512K sequence length: Approximately 240 ms.
* At 1M sequence length: Approximately 850 ms.
**MoBA (Dark Blue Solid Line):**
The line also slopes upward, but at a slower rate than Flash Attention.
* At 32K sequence length: Approximately 0 ms.
* At 128K sequence length: Approximately 20 ms.
* At 256K sequence length: Approximately 40 ms.
* At 512K sequence length: Approximately 100 ms.
* At 1M sequence length: Approximately 170 ms.
### Key Observations
* Flash Attention exhibits a significantly steeper increase in computation time as sequence length grows compared to MoBA.
* Both methods show relatively low computation times for shorter sequence lengths (32K and 128K).
* The difference in computation time between the two methods becomes more pronounced at longer sequence lengths (512K and 1M).
* MoBA consistently has lower computation times than Flash Attention across all sequence lengths tested.
### Interpretation
The data suggests that MoBA scales more efficiently with increasing sequence length than Flash Attention. While both methods are viable for shorter sequences, MoBA maintains a lower computational cost as the sequence length increases, making it potentially more suitable for applications dealing with very long sequences. The steep slope of Flash Attention indicates that its computational demands grow rapidly with sequence length, which could become a limiting factor in certain scenarios. The consistent difference in computation time between the two methods suggests a fundamental difference in their algorithmic complexity or implementation. The fact that both start at 0ms suggests that the overhead for both methods is minimal at the shortest sequence length.