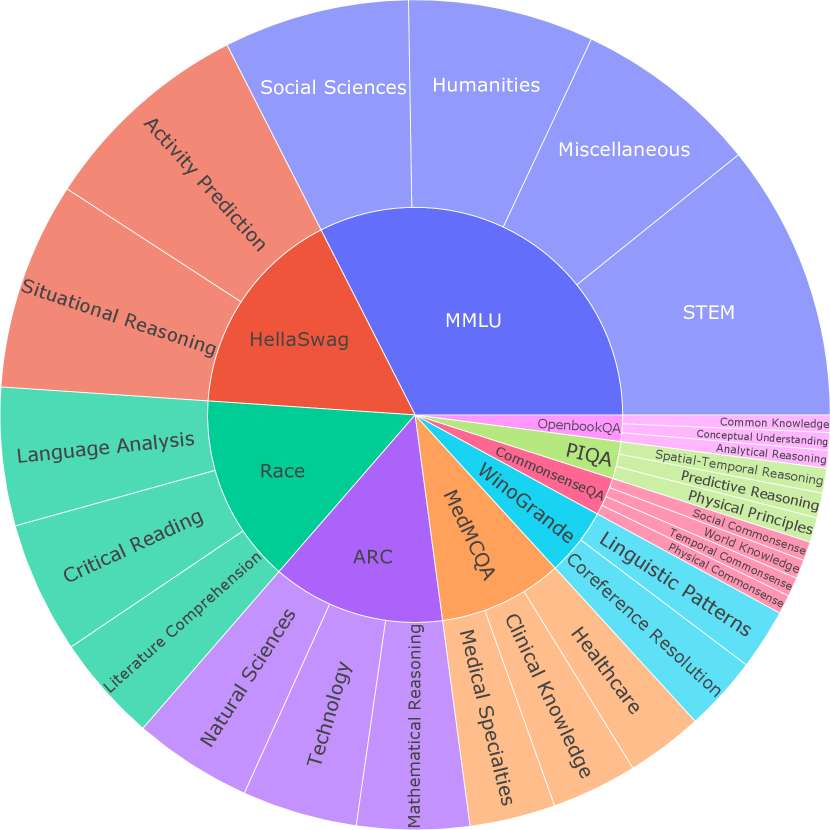
## Circular Partition Diagram: MMLU Task Distribution
### Overview
The image is a circular partition diagram illustrating the distribution of tasks within the MMLU (Massive Multitask Language Understanding) benchmark. The diagram is divided into concentric rings, with the inner rings representing broader categories and the outer rings representing more specific tasks. The size of each segment corresponds to the relative proportion of tasks within that category.
### Components/Axes
* **Center:** MMLU (Massive Multitask Language Understanding)
* **First Ring:**
* STEM (Science, Technology, Engineering, and Mathematics) - Light Blue
* Miscellaneous - Light Blue
* Humanities - Light Blue
* Social Sciences - Light Blue
* Activity Prediction - Salmon
* Situational Reasoning - Salmon
* Language Analysis - Teal
* Critical Reading - Teal
* Natural Sciences - Light Purple
* Technology - Light Purple
* Medical Specialties - Light Orange
* Healthcare - Light Orange
* Linguistic Patterns - Cyan
* Race - Green-Teal
* ARC - Purple
* HellaSwag - Red-Orange
* **Second Ring:**
* Literature Comprehension - Teal
* Mathematical Reasoning - Light Purple
* Clinical Knowledge - Light Orange
* Coreference Resolution - Cyan
* Physical Commonsense - Light Green
* World Knowledge - Light Green
* Temporal Commonsense - Light Green
* Social Commonsense - Light Green
* WinoGrande - Light Green
* CommonsenseQA - Light Green
* PIQA - Light Green
* OpenbookQA - Light Green
* Predictive Reasoning - Light Green
* Spatial-Temporal Reasoning - Light Green
* Analytical Reasoning - Light Green
* Conceptual Understanding - Light Green
* Common Knowledge - Light Green
* MedMCQA - Light Orange
### Detailed Analysis or Content Details
The diagram is structured as follows:
* **MMLU (Center):** The central node represents the overall MMLU benchmark.
* **Broad Categories (First Ring):** The first ring divides the tasks into broad categories such as STEM, Humanities, Social Sciences, Activity Prediction, Language Analysis, Natural Sciences, Technology, Medical Specialties, Linguistic Patterns, Race, ARC, and HellaSwag.
* **Specific Tasks (Second Ring):** The second ring further subdivides some of the broad categories into more specific tasks. For example, the area near "Linguistic Patterns" is subdivided into "Physical Commonsense", "World Knowledge", "Temporal Commonsense", "Social Commonsense", "WinoGrande", "CommonsenseQA", "PIQA", "OpenbookQA", "Predictive Reasoning", "Spatial-Temporal Reasoning", "Analytical Reasoning", "Conceptual Understanding", and "Common Knowledge".
**Color-Coded Categories:**
* **Light Blue:** STEM, Miscellaneous, Humanities, Social Sciences
* **Salmon:** Activity Prediction, Situational Reasoning
* **Teal:** Language Analysis, Critical Reading, Literature Comprehension
* **Light Purple:** Natural Sciences, Technology, Mathematical Reasoning
* **Light Orange:** Medical Specialties, Healthcare, Clinical Knowledge, MedMCQA
* **Cyan:** Linguistic Patterns, Coreference Resolution
* **Green-Teal:** Race
* **Purple:** ARC
* **Red-Orange:** HellaSwag
* **Light Green:** Common Knowledge, Conceptual Understanding, Analytical Reasoning, Spatial-Temporal Reasoning, Predictive Reasoning, Physical Principles, Social Commonsense, World Knowledge, Temporal Commonsense, Physical Commonsense, WinoGrande, CommonsenseQA, PIQA, OpenbookQA
### Key Observations
* The diagram provides a visual representation of the diversity of tasks included in the MMLU benchmark.
* The size of each segment reflects the relative proportion of tasks within that category.
* The color-coding helps to group related tasks together.
* The outer ring provides a more granular breakdown of specific tasks within certain categories.
### Interpretation
The circular partition diagram offers a clear overview of the MMLU benchmark's composition. It highlights the breadth of knowledge and reasoning abilities required to perform well on this benchmark. The diagram suggests that MMLU covers a wide range of subjects, from STEM fields to the humanities and social sciences, and includes tasks that require various types of reasoning, such as logical, spatial, and temporal reasoning. The distribution of tasks across different categories can provide insights into the strengths and weaknesses of different language models. For example, a model that performs well on STEM tasks but poorly on humanities tasks may have a bias towards scientific knowledge. The diagram also reveals the relative importance of different types of knowledge and reasoning in the MMLU benchmark. For instance, the large segment dedicated to STEM suggests that scientific knowledge is a significant component of the benchmark.