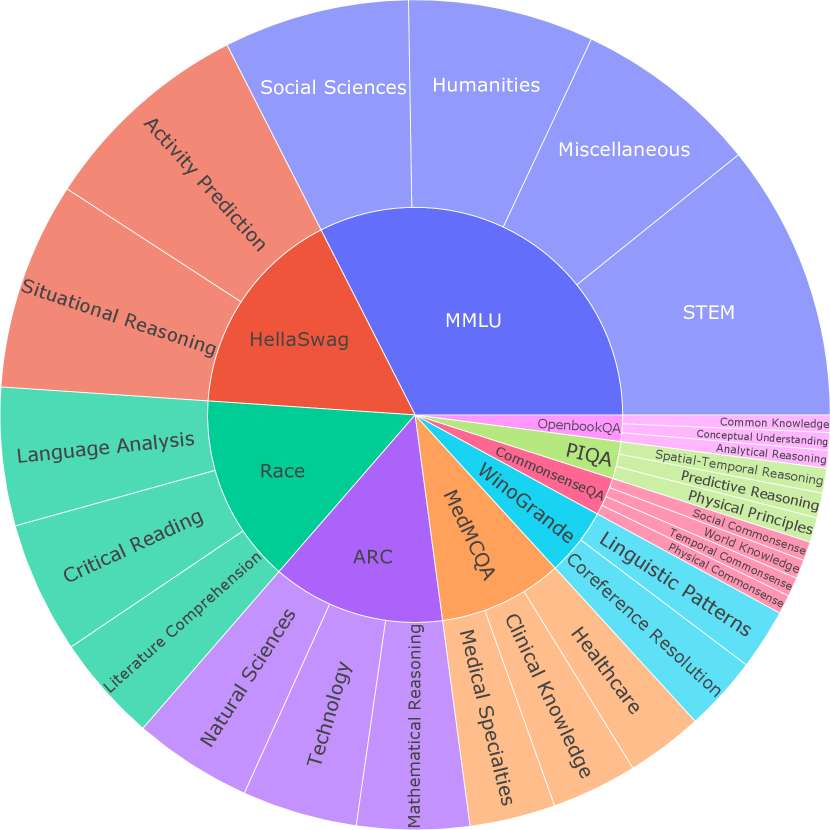
## Sunburst Chart: Distribution of AI Model Performance Across Tasks and Domains
### Overview
The chart visualizes the hierarchical distribution of AI model performance across two primary categories: **Tasks** (left side) and **Domains** (right side). Each category branches into subcategories, with segments connected to their parent nodes. The legend in the top-right corner maps colors to categories.
### Components/Axes
- **Main Categories**:
- **Tasks**: HellaSwag, Race, ARC, MedMCQA, WinoGrande, PIQA, OpenbookQA.
- **Domains**: MMLU, STEM, Humanities, Social Sciences, Miscellaneous.
- **Subcategories**:
- **Tasks**:
- HellaSwag: Situational Reasoning, Activity Prediction.
- Race: Language Analysis, Critical Reading, Literature Comprehension.
- ARC: Natural Sciences, Technology, Mathematical Reasoning.
- MedMCQA: Medical Specialties, Clinical Knowledge, Healthcare.
- WinoGrande: Coreference Resolution, Linguistic Patterns.
- PIQA: Social Commonsense, Physical Principles.
- OpenbookQA: Conceptual Understanding, Analytical Reasoning.
- **Domains**:
- MMLU: Mathematical Reasoning, Physical Principles, Social Commonsense.
- STEM: Mathematical Reasoning, Physical Principles.
- Humanities: Language Analysis, Critical Reading.
- Social Sciences: Situational Reasoning, Activity Prediction.
- Miscellaneous: Temporal Reasoning, Spatial Reasoning.
- **Legend**: Located in the top-right corner, with colors matching segments (e.g., HellaSwag = red, Race = teal, ARC = purple, MedMCQA = orange, WinoGrande = light blue, PIQA = green, OpenbookQA = pink; Domains: MMLU = dark blue, STEM = light blue, Humanities = purple, Social Sciences = red, Miscellaneous = green).
### Detailed Analysis
- **Tasks**:
- **HellaSwag** (red): Focuses on reasoning tasks (Situational Reasoning, Activity Prediction).
- **Race** (teal): Emphasizes language and comprehension skills (Language Analysis, Critical Reading, Literature Comprehension).
- **ARC** (purple): Covers scientific and mathematical reasoning (Natural Sciences, Technology, Mathematical Reasoning).
- **MedMCQA** (orange): Targets medical and healthcare domains (Medical Specialties, Clinical Knowledge, Healthcare).
- **WinoGrande** (light blue): Tests linguistic and coreference resolution skills.
- **PIQA** (green): Evaluates social and physical reasoning (Social Commonsense, Physical Principles).
- **OpenbookQA** (pink): Assesses conceptual and analytical understanding.
- **Domains**:
- **MMLU** (dark blue): Broad academic knowledge (Mathematical Reasoning, Physical Principles, Social Commonsense).
- **STEM** (light blue): Science and technology focus (Mathematical Reasoning, Physical Principles).
- **Humanities** (purple): Language and critical analysis (Language Analysis, Critical Reading).
- **Social Sciences** (red): Behavioral and situational reasoning (Situational Reasoning, Activity Prediction).
- **Miscellaneous** (green): Niche reasoning types (Temporal Reasoning, Spatial Reasoning).
### Key Observations
1. **Hierarchical Structure**: Tasks and Domains are interconnected, with subcategories nested under their parent nodes.
2. **Color Consistency**: All segments for a category share the same color (e.g., all HellaSwag subcategories are red).
3. **Subcategory Counts**:
- Tasks: 2–3 subcategories per category (e.g., HellaSwag = 2, Race = 3).
- Domains: 2–3 subcategories per domain (e.g., MMLU = 3, STEM = 2).
4. **Overlap**: Some subcategories appear in both Tasks and Domains (e.g., Mathematical Reasoning appears in ARC and STEM).
### Interpretation
The chart highlights the **diverse evaluation landscape for AI models**, emphasizing:
- **Task-Specific Performance**: Models are tested on specialized tasks (e.g., Medical Specialties, Coreference Resolution) and broader domains (e.g., STEM, Humanities).
- **Interdisciplinary Challenges**: Subcategories like Mathematical Reasoning and Physical Principles appear in both Tasks (ARC, PIQA) and Domains (STEM, MMLU), indicating cross-domain applicability.
- **Niche Focus**: Categories like Miscellaneous (Temporal/Spatial Reasoning) and OpenbookQA (Conceptual Understanding) suggest evaluation of less common but critical skills.
- **Color-Coded Clarity**: The legend ensures quick identification of categories, aiding in visual analysis of performance distribution.
This structure underscores the complexity of AI evaluation, balancing specificity (e.g., Medical Specialties) with generality (e.g., STEM), reflecting the multifaceted nature of real-world applications.