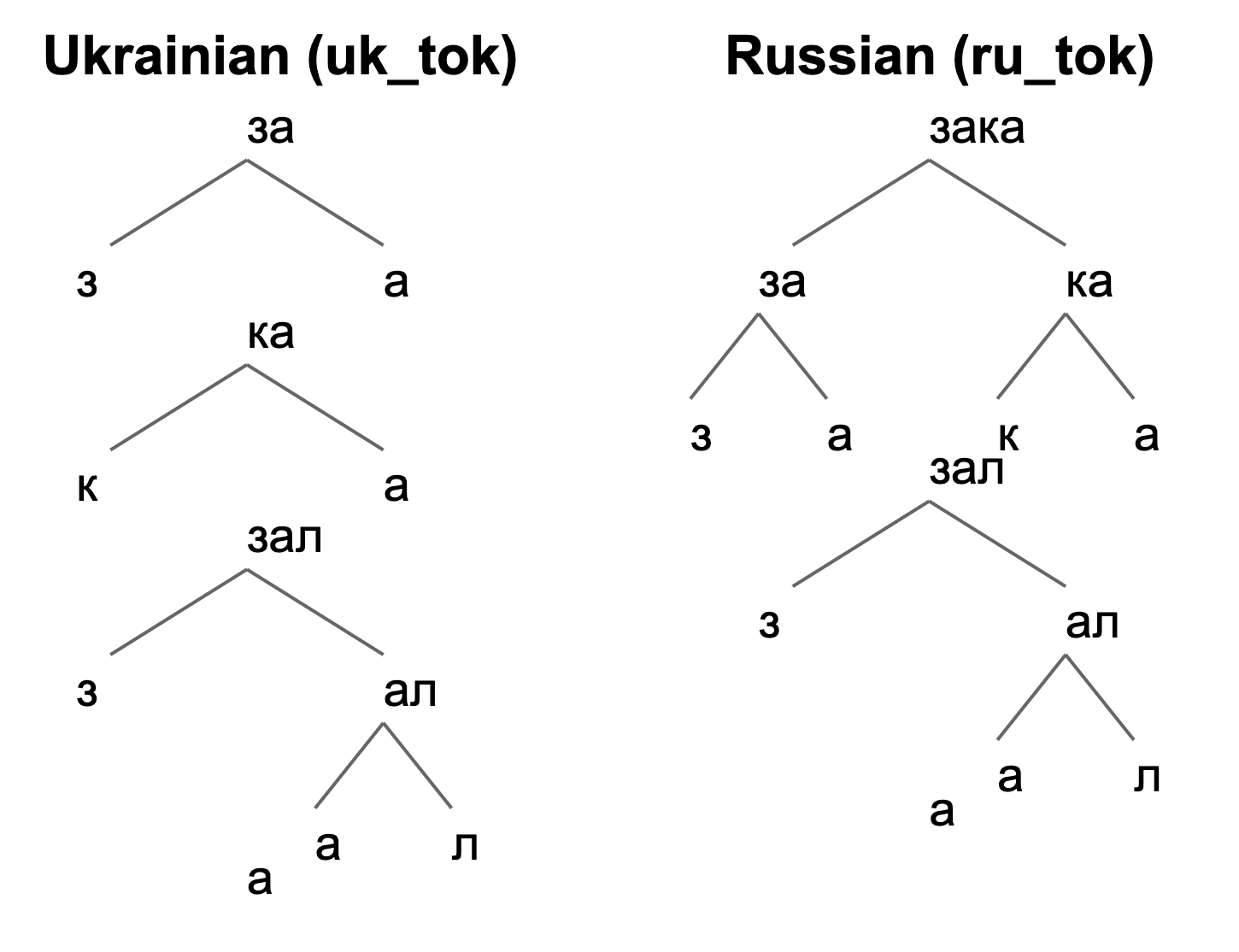
## Tree Diagram: Ukrainian vs. Russian Word Decomposition
### Overview
The image compares hierarchical decomposition structures for the word "зак" (Ukrainian: "tok," Russian: "tok") across three levels. Each language uses distinct alphabetic systems (Latin for Ukrainian, Cyrillic for Russian) and numerical annotations to represent phonetic or morphological breakdowns.
### Components/Axes
- **Titles**:
- Left: "Ukrainian (uk_tok)"
- Right: "Russian (ru_tok)"
- **Nodes**:
- **Ukrainian (Latin)**:
- Level 1: `3a` (root)
- Level 2: `ка` (ka)
- Level 3: `зал` (zal)
- **Russian (Cyrillic)**:
- Level 1: `зака` (3a)
- Level 2: `за` (za) and `ка` (ka)
- Level 3: `зал` (zal)
- **Connectors**: Lines represent hierarchical relationships between nodes.
### Detailed Analysis
#### Ukrainian (uk_tok)
1. **Root**: `3a` (3 + a)
2. **Second Level**: `ка` (ka)
3. **Third Level**: `зал` (zal)
- Subcomponents: `a` and `л` (l)
#### Russian (ru_tok)
1. **Root**: `зака` (3a)
2. **Second Level**:
- Left: `за` (za)
- Right: `ка` (ka)
3. **Third Level**: `зал` (zal)
- Subcomponents: `a` and `л` (l)
### Key Observations
1. **Structural Differences**:
- Ukrainian decomposition is linear (single branch per level).
- Russian decomposition splits into two branches at Level 2.
2. **Numerical Annotations**:
- `3` appears in both languages, possibly indicating syllable count or stress patterns.
3. **Alphabetic Systems**:
- Ukrainian uses Latin letters with diacritics (e.g., `3a`, `зал`).
- Russian uses Cyrillic letters (e.g., `зака`, `зал`).
### Interpretation
The diagrams likely illustrate phonetic or morphological segmentation of the word "зак" (token/word) in Ukrainian and Russian. The numerical `3` may denote syllable count (e.g., "за-ка" in Russian, "зак" in Ukrainian). The Cyrillic structure for Russian shows a bifurcation at Level 2, suggesting a split into consonant-vowel components (`за` + `ка`), while Ukrainian maintains a linear progression. This reflects differences in linguistic analysis frameworks between the two languages.
### Notable Patterns
- Both languages converge on `зал` (zal) at Level 3, indicating shared phonetic elements.
- Russian decomposition emphasizes consonant-vowel separation, whereas Ukrainian prioritizes linear progression.
- The use of `3` in both systems suggests a standardized metric (e.g., syllable count) for decomposition.