## Diagram: Self-Cognition Detection and Evaluation
### Overview
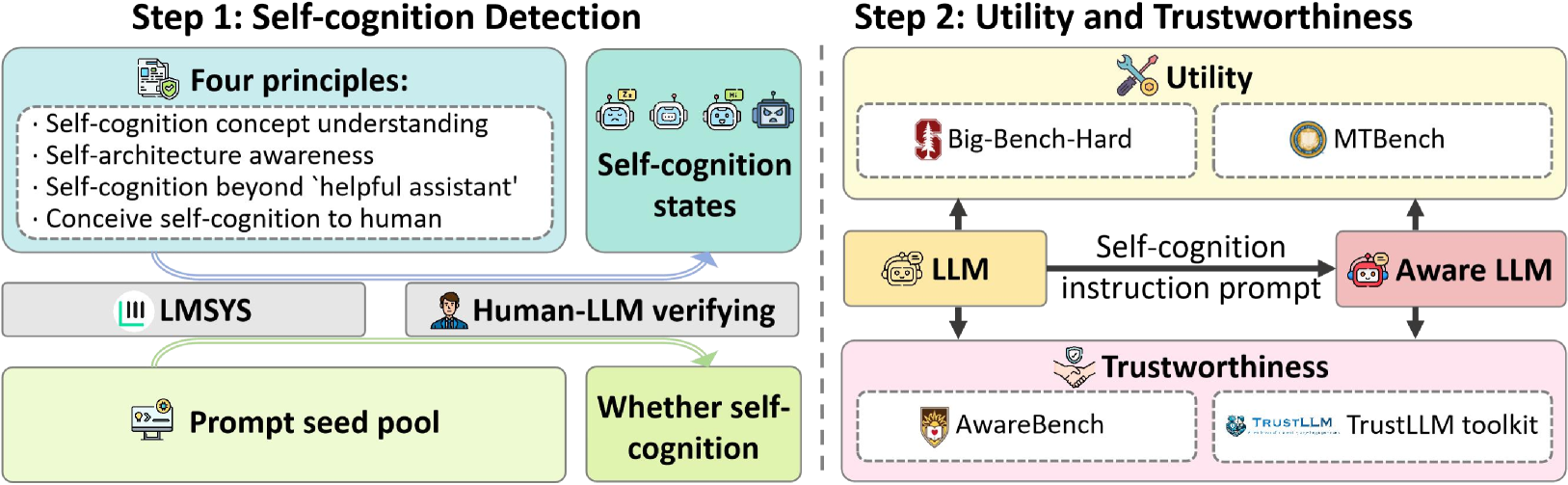
The image presents a two-step diagram outlining a process for self-cognition detection and evaluation in Large Language Models (LLMs). Step 1 focuses on self-cognition detection, while Step 2 assesses utility and trustworthiness. The diagram illustrates the flow of information and processes involved in each step.
### Components/Axes
**Step 1: Self-cognition Detection**
* **Title:** Step 1: Self-cognition Detection
* **Four Principles (Top-Left, Light Blue):**
* Self-cognition concept understanding
* Self-architecture awareness
* Self-cognition beyond 'helpful assistant'
* Conceive self-cognition to human
* **Self-cognition states (Top-Center, Light Blue):** Depicts four robot icons with different expressions.
* **LMSYS (Middle-Left, Gray):** A block labeled "LMSYS" with a logo.
* **Human-LLM verifying (Middle-Center, Gray):** A block labeled "Human-LLM verifying" with a human icon.
* **Prompt seed pool (Bottom-Left, Light Green):** A block labeled "Prompt seed pool" with a computer screen icon.
* **Whether self-cognition (Bottom-Center, Light Green):** A block labeled "Whether self-cognition".
* **Flow:** Arrows indicate the flow of information from the "Four Principles" and "Self-cognition states" to "LMSYS" and "Human-LLM verifying", which then leads to "Prompt seed pool" and "Whether self-cognition".
**Step 2: Utility and Trustworthiness**
* **Title:** Step 2: Utility and Trustworthiness
* **Utility (Top, Light Yellow):**
* Big-Bench-Hard (Left): A block with the Stanford University logo.
* MTBench (Right): A block with a coin icon.
* **LLM (Middle-Left, Light Yellow):** A block labeled "LLM" with a robot icon.
* **Self-cognition instruction prompt (Middle, Black Arrow):** Text describing the arrow connecting "LLM" to "Aware LLM".
* **Aware LLM (Middle-Right, Light Pink):** A block labeled "Aware LLM" with a robot icon.
* **Trustworthiness (Bottom, Light Pink):**
* AwareBench (Left): A block with a university logo.
* TrustLLM toolkit (Right): A block with a handshake and shield icon, labeled "TRUSTLLM TrustLLM toolkit".
* **Flow:** Arrows indicate the flow of information from "LLM" to "Aware LLM", and from "Aware LLM" back to "LLM". Arrows also connect "LLM" and "Aware LLM" to the "Utility" and "Trustworthiness" blocks.
### Detailed Analysis or Content Details
**Step 1: Self-cognition Detection**
* The "Four Principles" block outlines the key aspects considered for self-cognition.
* "Self-cognition states" visually represents different states or expressions of self-cognition.
* "LMSYS" and "Human-LLM verifying" likely represent methods or entities involved in verifying self-cognition.
* "Prompt seed pool" suggests a collection of prompts used in the detection process.
* "Whether self-cognition" represents the outcome of the detection process.
**Step 2: Utility and Trustworthiness**
* "Utility" and "Trustworthiness" are the two main aspects being evaluated.
* "Big-Bench-Hard" and "MTBench" are likely benchmark datasets or tools used to assess utility.
* "AwareBench" and "TrustLLM toolkit" are likely tools or frameworks used to assess trustworthiness.
* The flow between "LLM" and "Aware LLM" suggests an iterative process of prompting and evaluation.
### Key Observations
* The diagram presents a structured approach to self-cognition detection and evaluation.
* It highlights the importance of both utility and trustworthiness in assessing LLMs.
* The use of icons and visual elements makes the diagram easy to understand.
### Interpretation
The diagram illustrates a comprehensive framework for evaluating self-cognition in LLMs. Step 1 focuses on detecting self-cognition using a set of principles and verification methods. Step 2 then assesses the utility and trustworthiness of the LLM, using various benchmarks and toolkits. The iterative flow between "LLM" and "Aware LLM" suggests a process of continuous improvement and refinement. The diagram emphasizes the need to consider both the functional capabilities (utility) and ethical considerations (trustworthiness) of LLMs.