\n
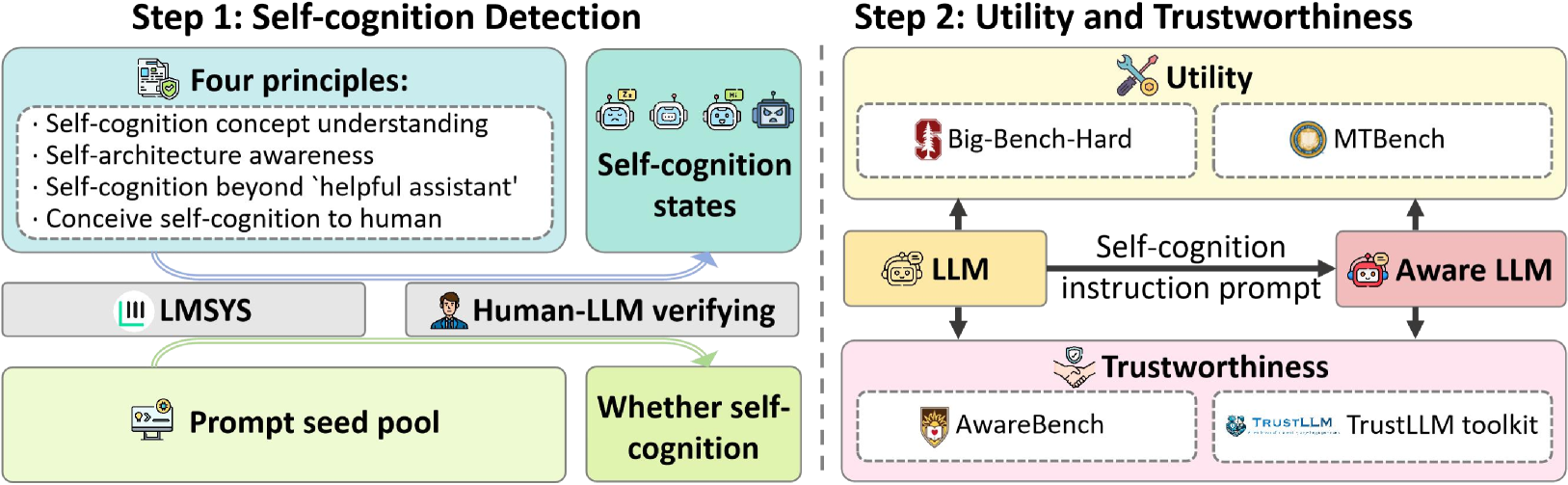
## Diagram: Self-Cognition Detection and Evaluation Pipeline
### Overview
This diagram illustrates a two-step pipeline for evaluating Large Language Models (LLMs) based on self-cognition, utility, and trustworthiness. The first step focuses on detecting self-cognition, while the second step assesses utility and trustworthiness using various benchmarks and tools. The diagram uses a flowchart-style representation with boxes representing processes or components and arrows indicating the flow of information.
### Components/Axes
The diagram is divided into two main steps: "Step 1: Self-cognition Detection" and "Step 2: Utility and Trustworthiness".
**Step 1 Components:**
* **Four principles:** A list of four principles related to self-cognition.
* **Self-cognition states:** A central box representing the identified self-cognition states.
* **LMSYS:** A teal-colored box representing the LMSYS component.
* **Human-LLM verifying:** A light-blue box representing human verification of LLM responses.
* **Prompt seed pool:** A green box representing a pool of prompts used as input.
* **Whether self-cognition:** A box indicating the outcome of the self-cognition detection process.
**Step 2 Components:**
* **Utility:** A section dedicated to evaluating the utility of the LLM.
* **Big-Bench-Hard:** A benchmark for assessing LLM capabilities.
* **MTBench:** Another benchmark for evaluating LLM performance.
* **LLM:** A purple box representing the LLM being evaluated.
* **Aware LLM:** A red box representing an aware LLM.
* **Self-cognition instruction prompt:** A box indicating the prompt used to elicit self-cognition.
* **Trustworthiness:** A section dedicated to evaluating the trustworthiness of the LLM.
* **AwareBench:** A benchmark for assessing trustworthiness.
* **TrustLLM:** A tool for evaluating trustworthiness.
* **TrustLLM toolkit:** A collection of tools for trustworthiness assessment.
### Detailed Analysis or Content Details
**Step 1: Self-cognition Detection**
* The "Four principles" are listed as:
* Self-cognition concept understanding
* Self-architecture awareness
* Self-cognition beyond 'helpful assistant'
* Conceive self-cognition to human
* The "Prompt seed pool" feeds into both "LMSYS" and "Human-LLM verifying".
* Both "LMSYS" and "Human-LLM verifying" contribute to determining "Whether self-cognition".
* The output of "Whether self-cognition" feeds into the "Self-cognition states" box.
**Step 2: Utility and Trustworthiness**
* The "LLM" receives a "Self-cognition instruction prompt" and outputs to both "Utility" and "Trustworthiness" sections.
* The "Utility" section utilizes "Big-Bench-Hard" and "MTBench" to evaluate the LLM.
* The "Trustworthiness" section utilizes "AwareBench", "TrustLLM", and "TrustLLM toolkit" to evaluate the LLM.
* An "Aware LLM" is also shown as a separate output from the "Self-cognition instruction prompt", feeding into both "Utility" and "Trustworthiness".
### Key Observations
* The diagram highlights a two-stage process: first detecting self-cognition, then evaluating utility and trustworthiness *based* on that self-cognition.
* Both human verification and automated systems (LMSYS) are used in the self-cognition detection phase.
* Multiple benchmarks and tools are employed to assess both utility and trustworthiness, suggesting a comprehensive evaluation approach.
* The "Aware LLM" appears to be a distinct output, potentially representing an LLM specifically designed with self-awareness.
### Interpretation
This diagram outlines a methodology for evaluating LLMs beyond traditional performance metrics. It proposes that assessing self-cognition is a crucial first step, and that utility and trustworthiness should be evaluated *in the context* of that self-cognition. The use of both human and automated evaluation methods suggests a desire for robust and reliable results. The inclusion of an "Aware LLM" indicates an interest in developing LLMs that possess a degree of self-awareness, and understanding how that impacts their behavior and capabilities. The diagram suggests a shift towards more nuanced and holistic evaluation of LLMs, moving beyond simply measuring accuracy and efficiency to considering their cognitive abilities and ethical implications. The flow suggests that the self-cognition detection is a prerequisite for the subsequent utility and trustworthiness assessments, implying that these latter qualities are dependent on, or at least influenced by, the LLM's self-awareness.