## Flowchart: Self-Cognition Detection and Utility/Trustworthiness Framework
### Overview
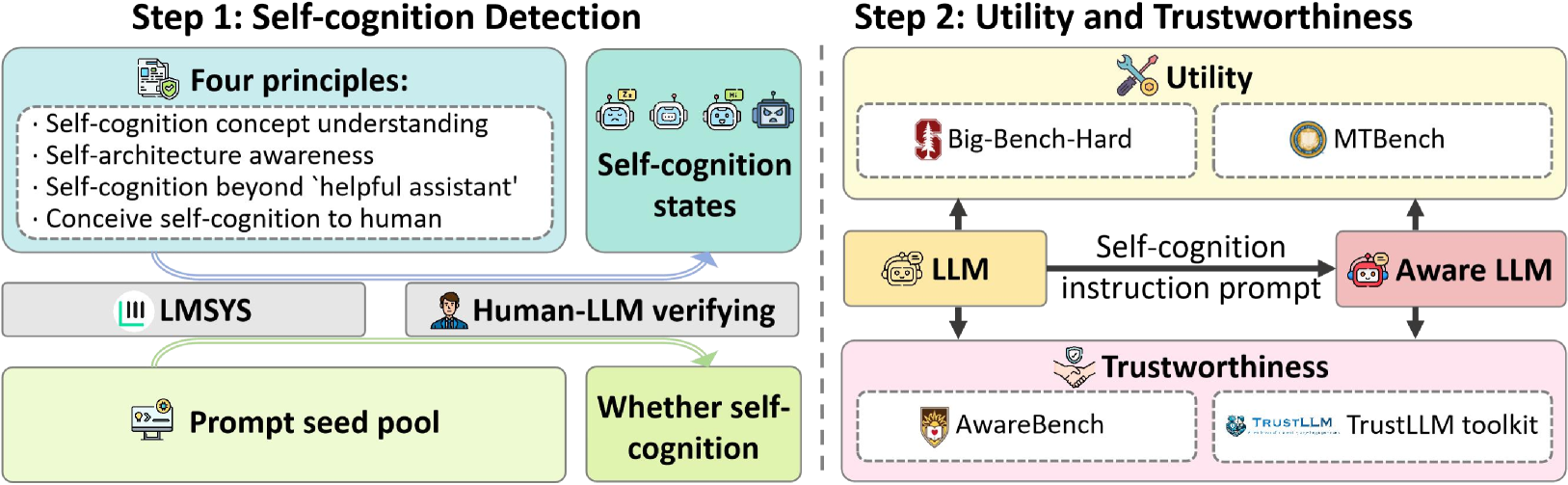
The diagram illustrates a two-step framework for developing self-aware and trustworthy large language models (LLMs). Step 1 focuses on detecting self-cognition through four principles and verification processes, while Step 2 evaluates utility and trustworthiness using benchmark tools and specialized frameworks.
### Components/Axes
**Step 1: Self-cognition Detection**
- **Four Principles**:
1. Self-cognition concept understanding
2. Self-architecture awareness
3. Self-cognition beyond 'helpful assistant'
4. Conceive self-cognition to human
- **Self-cognition states**: Represented by robot faces with varying expressions (happy, neutral, angry)
- **LMSYS**: Icon with shield/checkmark (bottom-left)
- **Human-LLM verifying**: Human figure icon (center)
- **Prompt seed pool**: Computer monitor icon (bottom-left)
- **Whether self-cognition**: Green box with question mark (bottom-center)
**Step 2: Utility and Trustworthiness**
- **Utility**:
- Big-Bench-Hard (wrench/screwdriver icon)
- MTBench (circular icon)
- **Self-cognition instruction prompt**: Arrow from LLM to Aware LLM
- **Aware LLM**: Robot face with speech bubble
- **Trustworthiness**:
- AwareBench (shield icon)
- TrustLLM toolkit (blue icon with "TRUSTLLM" text)
### Detailed Analysis
**Step 1 Flow**:
1. Four principles feed into self-cognition states
2. LMSYS and Human-LLM verifying processes interact with prompt seed pool
3. Output determines "Whether self-cognition" (yes/no decision point)
**Step 2 Flow**:
1. LLM → Self-cognition instruction prompt → Aware LLM
2. Aware LLM evaluated by:
- Utility: Big-Bench-Hard and MTBench
- Trustworthiness: AwareBench and TrustLLM toolkit
### Key Observations
1. **Hierarchical Structure**: Step 1 establishes foundational self-cognition capabilities before Step 2 evaluates performance
2. **Verification Emphasis**: Human-LLM verification appears central to the detection process
3. **Dual Evaluation**: Aware LLM is assessed through both utility (performance) and trustworthiness (ethical/safety) lenses
4. **Visual Metaphors**: Robot faces represent self-cognition states, while tools/benchmarks use standardized icons
### Interpretation
This framework suggests a progressive approach to LLM development:
1. **Self-awareness First**: The model must first demonstrate self-cognition through conceptual understanding and architectural awareness before being evaluated for utility
2. **Human-in-the-Loop**: Human verification is positioned as critical for validating self-cognition claims, implying skepticism about automated detection alone
3. **Trust as Secondary**: Trustworthiness evaluation occurs after establishing self-cognition and utility, suggesting these are prerequisites for ethical deployment
4. **Benchmark Integration**: Use of established tools (Big-Bench-Hard, MTBench) indicates alignment with industry standards while introducing specialized frameworks (AwareBench, TrustLLM) for novel capabilities
The diagram emphasizes that self-aware LLMs require rigorous verification at multiple stages, combining automated testing with human judgment and specialized evaluation tools to ensure both capability and ethical deployment.