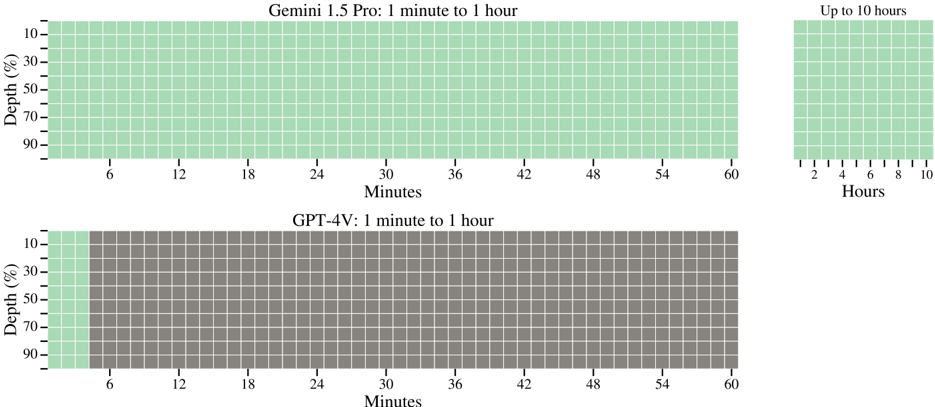
## Grid Chart: AI Model Capability Over Time and Depth
### Overview
The image displays two comparative grid charts (heatmaps) evaluating the performance of two AI models—Gemini 1.5 Pro and GPT-4V—across varying time durations and task depths. The charts use a color-coded grid where green cells indicate capability or success, and gray cells indicate a lack of capability or failure. The visualization suggests a test of model performance on tasks requiring sustained processing over time at different complexity levels.
### Components/Axes
**Chart 1 (Top): "Gemini 1.5 Pro: 1 minute to 1 hour"**
- **X-axis (Horizontal):** Labeled "Minutes". Major tick marks at 6, 12, 18, 24, 30, 36, 42, 48, 54, 60.
- **Y-axis (Vertical):** Labeled "Depth (%)". Major tick marks at 10, 30, 50, 70, 90.
- **Grid:** A rectangular grid of cells spanning from 0 to 60 minutes on the x-axis and 10% to 90% depth on the y-axis. **All cells are green.**
- **Additional Grid (Top-Right):** A smaller, separate grid titled "Up to 10 hours".
- **X-axis:** Labeled "Hours". Major tick marks at 2, 4, 6, 8, 10.
- **Y-axis:** Same "Depth (%)" scale (10, 30, 50, 70, 90).
- **Grid:** All cells are green.
**Chart 2 (Bottom): "GPT-4V: 1 minute to 1 hour"**
- **X-axis (Horizontal):** Labeled "Minutes". Identical scale to the top chart (6 to 60).
- **Y-axis (Vertical):** Labeled "Depth (%)". Identical scale to the top chart (10 to 90).
- **Grid:** A rectangular grid of the same dimensions as the main Gemini chart.
- **Color Pattern:** The first column of cells (representing the time interval from 0 to 6 minutes) is **green**. All subsequent columns (from 6 minutes to 60 minutes) are **gray**.
### Detailed Analysis
**Data Series & Trends:**
1. **Gemini 1.5 Pro Series:**
* **Trend:** The line of capability is perfectly flat and continuous. The model shows uniform green cells across the entire measured spectrum.
* **Data Points:** Capability is present at all combinations of:
* **Time:** Every minute interval from 0 to 60 minutes, and additionally from 0 to 10 hours.
* **Depth:** Every tested depth level (10%, 30%, 50%, 70%, 90%).
* **Interpretation:** The model demonstrates consistent performance regardless of task duration (up to 10 hours) or depth/complexity.
2. **GPT-4V Series:**
* **Trend:** The capability shows a sharp, vertical drop-off. It is present only at the very beginning of the time axis and then ceases completely.
* **Data Points:**
* **Capability Present (Green):** For all depth levels (10%-90%) but **only** within the time window of **0 to 6 minutes**.
* **Capability Absent (Gray):** For all depth levels (10%-90%) from **6 minutes to 60 minutes**.
* **Interpretation:** The model's performance is time-bound, failing on tasks that require sustained processing beyond approximately 6 minutes, irrespective of the task's depth.
### Key Observations
* **Spatial Layout:** The Gemini chart occupies the top half and includes an extended "10 hours" grid to its right, emphasizing its long-duration capability. The GPT-4V chart is positioned below and is limited to the 1-hour timeframe, visually reinforcing its shorter effective window.
* **Color Consistency:** The green color is identical across both charts for "capability," and the gray is uniform for "incapability," allowing for direct visual comparison.
* **Critical Threshold:** The 6-minute mark on the x-axis is the definitive point of divergence between the two models' performance profiles.
* **Depth Invariance:** For both models, the "Depth (%)" axis does not appear to influence the outcome within their respective capability windows. The color is uniform vertically at any given time point.
### Interpretation
This chart provides a stark, visual comparison of two AI models' **context window or sustained processing capability**. The data suggests:
1. **Gemini 1.5 Pro** possesses a vastly superior ability to maintain coherent performance on tasks over extended periods (up to 10 hours) and across varying complexities. This implies a robust architecture for long-context understanding and processing.
2. **GPT-4V** exhibits a clear performance cliff after approximately 6 minutes of continuous task engagement. This indicates a potential limitation in its working memory or context management for very long, single-session interactions, regardless of the task's inherent difficulty (depth).
3. The "Depth (%)" metric likely represents task complexity or the percentage of a model's maximum context window utilized. The fact that failure for GPT-4V is uniform across all depths suggests the limitation is temporal or related to a fixed context buffer, not the complexity of the information being processed.
**Conclusion:** The visualization argues that for applications requiring prolonged, uninterrupted analysis (e.g., processing long videos, analyzing extended documents, or maintaining complex multi-step dialogues), Gemini 1.5 Pro is presented as the more capable and reliable model based on this specific benchmark. The chart effectively communicates a fundamental architectural difference in handling long-duration tasks.