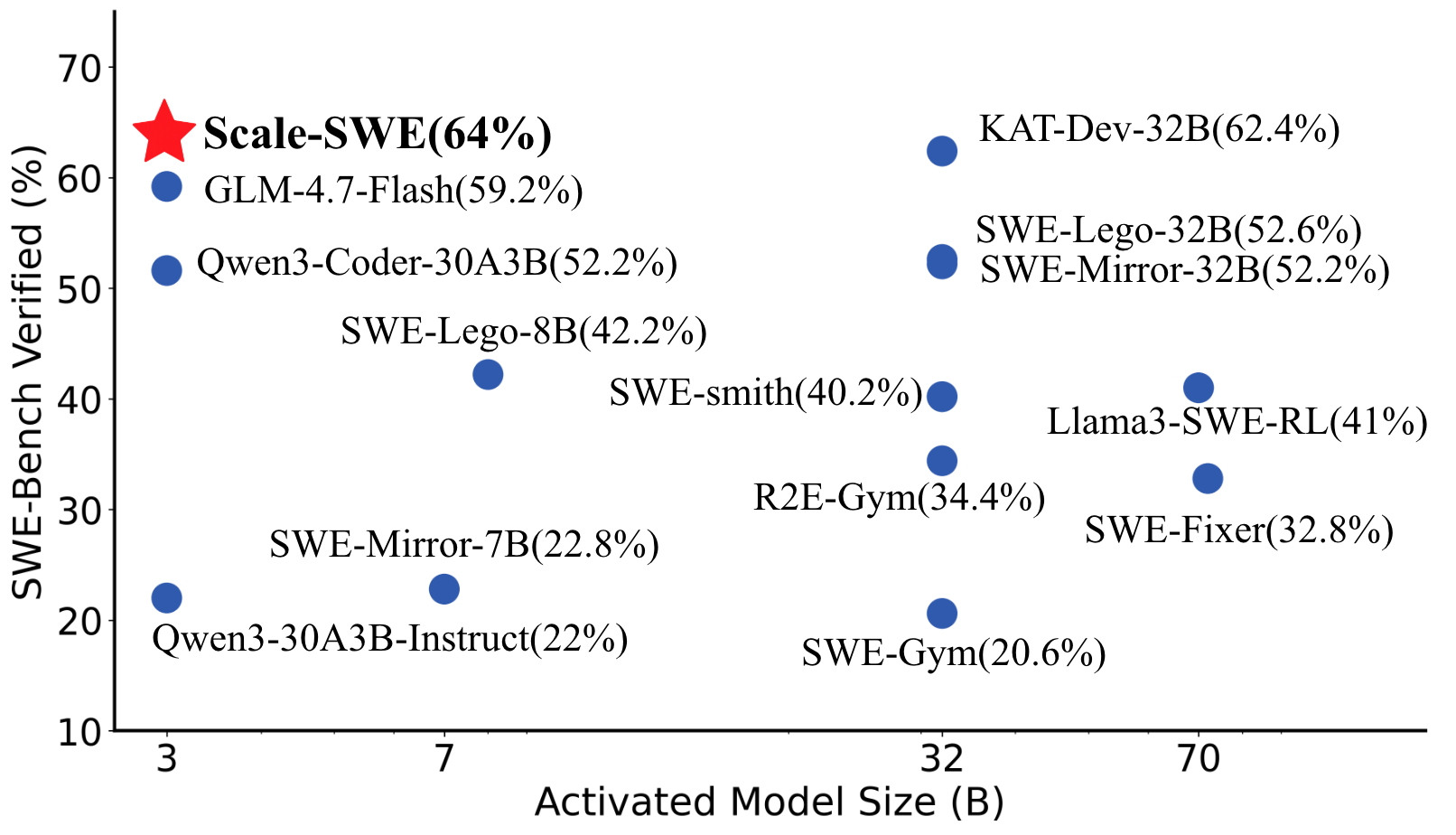
## Scatter Plot: SWE-Bench Verified vs. Activated Model Size
### Overview
This scatter plot visualizes the relationship between the Activated Model Size (in Billions - B) and the percentage of SWE-Bench Verified for various models. The plot displays data points representing different models, with their corresponding sizes and verification percentages. A red star highlights a model named "Scale-SWE" with a notably high verification percentage.
### Components/Axes
* **X-axis:** Activated Model Size (B) - Ranges from approximately 3 to 70.
* **Y-axis:** SWE-Bench Verified (%) - Ranges from approximately 10% to 70%.
* **Data Points:** Blue circles representing individual models.
* **Highlight:** A red star representing the "Scale-SWE" model.
* **Labels:** Each data point is labeled with the model name and its SWE-Bench Verified percentage.
### Detailed Analysis
The data points are scattered across the plot, showing a general trend of increasing SWE-Bench Verified percentage with increasing Activated Model Size, but with significant variance.
Here's a breakdown of the data points, reading from left to right (approximately):
* **Qwen3-30A3B-Instruct:** Activated Model Size ≈ 3B, SWE-Bench Verified ≈ 22%.
* **SWE-Mirror-7B:** Activated Model Size ≈ 7B, SWE-Bench Verified ≈ 22.8%.
* **GLM-4.7-Flash:** Activated Model Size ≈ 7B, SWE-Bench Verified ≈ 59.2%.
* **Qwen3-Coder-30A3B:** Activated Model Size ≈ 7B, SWE-Bench Verified ≈ 52.2%.
* **SWE-Lego-8B:** Activated Model Size ≈ 7B, SWE-Bench Verified ≈ 42.2%.
* **SWE-Gym:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 20.6%.
* **R2E-Gym:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 34.4%.
* **SWE-smith:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 40.2%.
* **Llama3-SWE-RL:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 41%.
* **SWE-Fixer:** Activated Model Size ≈ 70B, SWE-Bench Verified ≈ 32.8%.
* **KAT-Dev-32B:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 62.4%.
* **SWE-Lego-32B:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 52.6%.
* **SWE-Mirror-32B:** Activated Model Size ≈ 32B, SWE-Bench Verified ≈ 52.2%.
* **Scale-SWE:** Activated Model Size ≈ 64B, SWE-Bench Verified ≈ 64%. (Highlighted with a red star)
### Key Observations
* **Scale-SWE** significantly outperforms all other models, achieving the highest SWE-Bench Verified percentage (64%) with a model size of 64B.
* There's a wide range of SWE-Bench Verified percentages for models with similar Activated Model Sizes (e.g., around 32B).
* The relationship between model size and verification percentage isn't strictly linear; larger models don't always guarantee higher verification.
* Models with smaller sizes (around 3-7B) generally have lower verification percentages.
### Interpretation
The data suggests that while increasing the Activated Model Size generally correlates with improved SWE-Bench verification, it's not the sole determinant of performance. The "Scale-SWE" model demonstrates that specific architectural choices or training methodologies can lead to substantial gains in verification accuracy, even at comparable model sizes. The variance in verification percentages for models of similar sizes indicates that factors beyond size, such as training data, model architecture, and optimization techniques, play a crucial role. The plot highlights the importance of considering multiple factors when evaluating and comparing language models. The red star draws attention to a model that is an outlier in terms of performance, suggesting it may be a particularly effective or well-optimized model. The data could be used to inform decisions about model selection and resource allocation, guiding developers towards models that offer the best balance between size and performance.