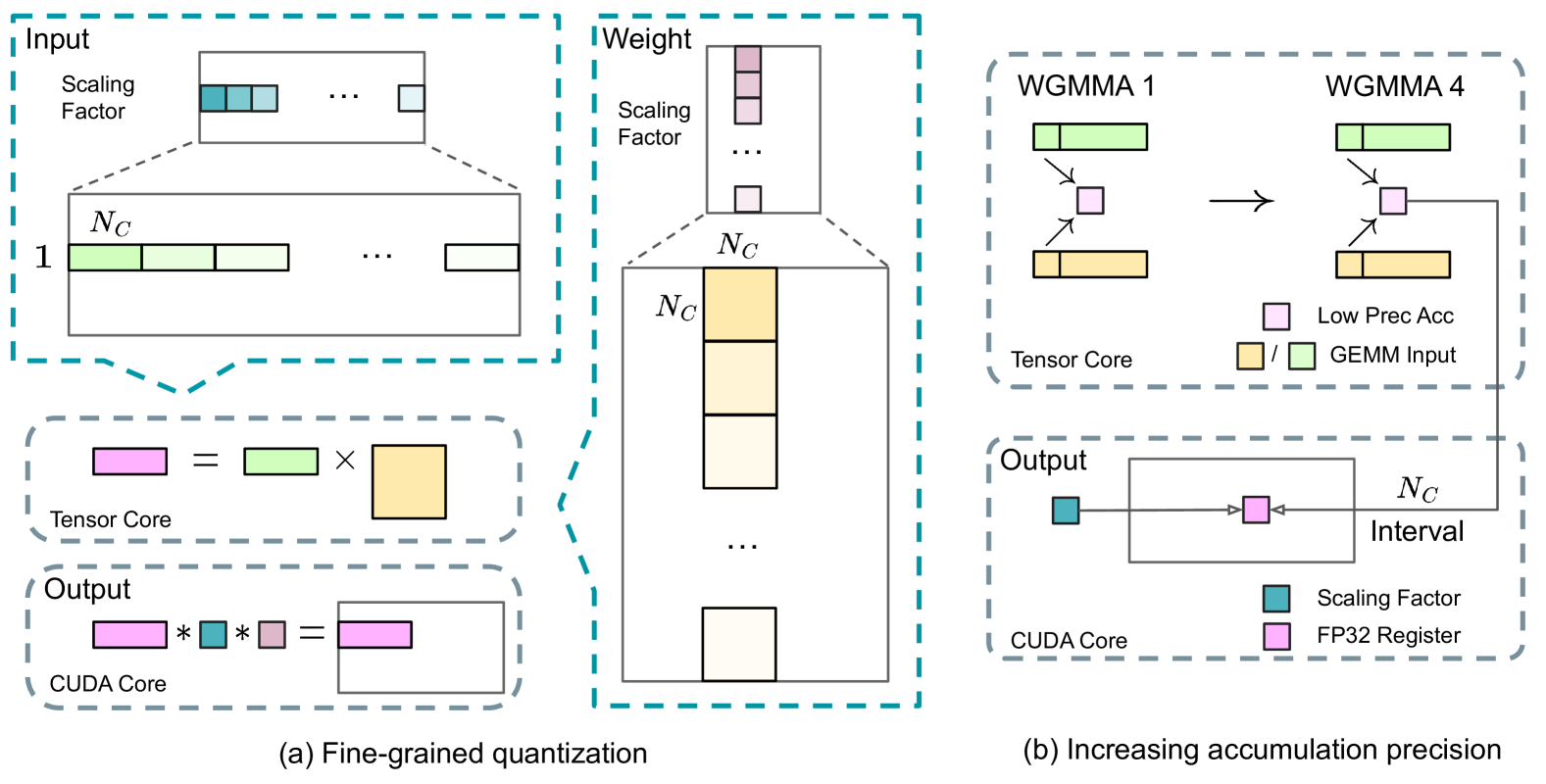
# Technical Document Extraction: Quantization and Accumulation Precision Diagrams
This document provides a detailed technical extraction of the provided image, which illustrates two methods for optimizing neural network computations: (a) Fine-grained quantization and (b) Increasing accumulation precision.
---
## General Information
- **Language:** English
- **Primary Components:** Two main sub-figures labeled (a) and (b).
- **Context:** High-performance computing, specifically focusing on Tensor Core and CUDA Core operations for General Matrix Multiplication (GEMM).
---
## (a) Fine-grained Quantization
This section describes the data structure and processing flow for quantized matrix multiplication.
### 1. Input Component (Top Left)
* **Structure:** A large horizontal matrix labeled with a height of **1** and a width segment labeled **$N_C$**.
* **Scaling Factor:** Above the main matrix is a smaller vector representing "Scaling Factor." It contains teal-colored blocks.
* **Relationship:** The diagram shows a zoomed-in view where a specific segment of the input matrix (length $N_C$) corresponds to a specific teal scaling factor block.
### 2. Weight Component (Center)
* **Structure:** A large vertical matrix. A vertical segment is labeled with height **$N_C$** and width **$N_C$**.
* **Scaling Factor:** Above the weight matrix is a vertical vector of "Scaling Factor" blocks (light pink/purple).
* **Relationship:** A specific $N_C \times N_C$ block in the weight matrix (highlighted in yellow) corresponds to a specific scaling factor in the vector above.
### 3. Tensor Core Operation (Middle Left)
* **Equation:** [Pink Rectangle] = [Green Rectangle] $\times$ [Yellow Square]
* **Label:** "Tensor Core"
* **Description:** Represents the low-precision matrix multiplication performed by the Tensor Core using the quantized inputs and weights.
### 4. Output Component (Bottom Left)
* **Equation:** [Pink Rectangle] $*$ [Teal Square] $*$ [Light Purple Square] = [Resultant Pink/Purple Rectangle]
* **Label:** "CUDA Core"
* **Description:** This represents the de-quantization step. The low-precision result from the Tensor Core is multiplied by the Input Scaling Factor (Teal) and the Weight Scaling Factor (Light Purple) to produce the final output in a larger matrix.
---
## (b) Increasing Accumulation Precision
This section describes the evolution of Warpgroup Matrix Multiply-Accumulate (WGMMA) operations to improve precision.
### 1. WGMMA Comparison (Top Right)
* **WGMMA 1:** Shows a Green GEMM input and an Orange GEMM input feeding into a single Pink "Low Prec Acc" (Low Precision Accumulator) block.
* **WGMMA 4:** Shows the same inputs, but the output Pink block is part of a larger flow. An arrow indicates that the result of the accumulation is passed down to the next stage.
* **Legend (Spatial Grounding: Bottom right of this sub-section):**
* **Pink Square:** Low Prec Acc (Low Precision Accumulator)
* **Yellow / Green Squares:** GEMM Input
* **Label:** "Tensor Core"
### 2. Output and Precision Refinement (Bottom Right)
* **Components:**
* A horizontal rectangle labeled **$N_C$ Interval**.
* Inside the rectangle is a Pink block (Low Prec Acc).
* A Teal block labeled **Scaling Factor** is on the left.
* A Pink block labeled **FP32 Register** is on the right.
* **Flow:** The output from "WGMMA 4" (Tensor Core) feeds into the $N_C$ Interval block.
* **Label:** "CUDA Core"
* **Legend (Spatial Grounding: Bottom right of this sub-section):**
* **Teal Square:** Scaling Factor
* **Pink Square:** FP32 Register
---
## Summary of Key Data and Labels
| Category | Labels / Components |
| :--- | :--- |
| **Mathematical Variables** | $N_C$, 1 |
| **Hardware Units** | Tensor Core, CUDA Core |
| **Data Types/Roles** | Scaling Factor, GEMM Input, Low Prec Acc, FP32 Register, $N_C$ Interval |
| **Operations** | WGMMA 1, WGMMA 4, Multiplication ($\times$), Scalar Multiplication ($*$) |
### Visual Trend Verification
* **Quantization Flow:** The diagram moves from high-level matrix structures (Input/Weight) to specific hardware operations (Tensor Core) and finally to de-quantization (CUDA Core).
* **Precision Flow:** The diagram shows a transition from a simple accumulation (WGMMA 1) to a more complex, higher-precision accumulation (WGMMA 4) that integrates with FP32 registers for better numerical stability over an $N_C$ interval.