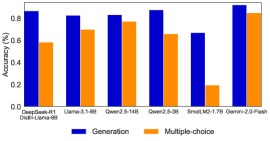
## Bar Chart: Model Performance Comparison (Generation vs Multiple-choice Accuracy)
### Overview
The chart compares the accuracy of six AI models across two tasks: Generation and Multiple-choice. Models are listed on the x-axis, with accuracy percentages (0-100%) on the y-axis. Blue bars represent Generation accuracy, while orange bars represent Multiple-choice accuracy.
### Components/Axes
- **X-axis**: Model names (DeepSeek-R1, Llama-3-1-8B, Qwen2.5-14B, Qwen2.5-3B, SmolLM2-1.7B, Gemini-2.0-Flash)
- **Y-axis**: Accuracy (%) from 0.0 to 0.8 in 0.2 increments
- **Legend**:
- Blue = Generation
- Orange = Multiple-choice
- **Legend Position**: Bottom center
### Detailed Analysis
1. **DeepSeek-R1**
- Generation: ~0.85
- Multiple-choice: ~0.6
2. **Llama-3-1-8B**
- Generation: ~0.82
- Multiple-choice: ~0.7
3. **Qwen2.5-14B**
- Generation: ~0.83
- Multiple-choice: ~0.78
4. **Qwen2.5-3B**
- Generation: ~0.88
- Multiple-choice: ~0.65
5. **SmolLM2-1.7B**
- Generation: ~0.67
- Multiple-choice: ~0.2
6. **Gemini-2.0-Flash**
- Generation: ~0.92
- Multiple-choice: ~0.85
### Key Observations
- **Trend Verification**:
- Generation accuracy consistently exceeds Multiple-choice for all models except Gemini-2.0-Flash (where both are high).
- Qwen2.5-3B shows the largest gap between tasks (0.88 vs 0.65).
- SmolLM2-1.7B has the lowest Multiple-choice accuracy (0.2), creating an outlier.
### Interpretation
1. **Task Performance**: Generation tasks generally show higher accuracy across models, suggesting they may be better suited to these architectures or training objectives.
2. **Model Specialization**: Gemini-2.0-Flash dominates both tasks, indicating superior design or training for complex reasoning.
3. **Outlier Analysis**: SmolLM2-1.7B's drastic drop in Multiple-choice accuracy (0.2 vs 0.67 Generation) suggests potential limitations in handling structured reasoning tasks.
4. **Model Size Correlation**: Larger models (e.g., Gemini-2.0-Flash, Qwen2.5-14B) tend to perform better in both tasks, though exceptions exist (Qwen2.5-3B underperforms in Multiple-choice despite high Generation accuracy).
### Technical Implications
- The data highlights trade-offs between task types and model capabilities.
- Gemini-2.0-Flash's performance suggests it may be optimized for both open-ended and constrained reasoning.
- SmolLM2-1.7B's results warrant investigation into architectural constraints or training data biases affecting Multiple-choice performance.