\n
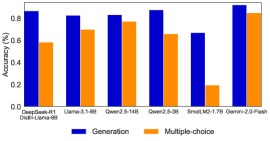
## Bar Chart: Model Accuracy Comparison
### Overview
This image presents a bar chart comparing the accuracy of several language models on two different task types: "Generation" and "Multiple-choice". The accuracy is measured as a percentage, ranging from 0.0 to 1.0. The chart displays the accuracy scores for each model and task type using adjacent bars.
### Components/Axes
* **X-axis:** Model Names - DeepSeek-R1, Llama-3.1-6B, Qwen-2.5-14B, Qwen-2.5-3B, SmalLM2-1.7B, Gemini-2.0-Flash. Below each model name is a secondary label: "Dwebi-Llama-8B" appears under "DeepSeek-R1".
* **Y-axis:** Accuracy (%) - Scale ranges from 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located at the bottom-center of the chart.
* Blue: Generation
* Orange: Multiple-choice
### Detailed Analysis
The chart consists of six sets of paired bars, one for each model. The blue bars represent the "Generation" accuracy, and the orange bars represent the "Multiple-choice" accuracy.
* **DeepSeek-R1 (Dwebi-Llama-8B):**
* Generation: Approximately 0.64 (±0.02)
* Multiple-choice: Approximately 0.60 (±0.02)
* **Llama-3.1-6B:**
* Generation: Approximately 0.83 (±0.02)
* Multiple-choice: Approximately 0.72 (±0.02)
* **Qwen-2.5-14B:**
* Generation: Approximately 0.86 (±0.02)
* Multiple-choice: Approximately 0.78 (±0.02)
* **Qwen-2.5-3B:**
* Generation: Approximately 0.90 (±0.02)
* Multiple-choice: Approximately 0.68 (±0.02)
* **SmalLM2-1.7B:**
* Generation: Approximately 0.68 (±0.02)
* Multiple-choice: Approximately 0.20 (±0.02)
* **Gemini-2.0-Flash:**
* Generation: Approximately 0.92 (±0.02)
* Multiple-choice: Approximately 0.84 (±0.02)
The "Generation" bars generally trend upwards from left to right, with the exception of DeepSeek-R1 and SmalLM2-1.7B. The "Multiple-choice" bars show more variability.
### Key Observations
* Gemini-2.0-Flash exhibits the highest accuracy for both "Generation" (approximately 0.92) and "Multiple-choice" (approximately 0.84).
* SmalLM2-1.7B performs poorly on the "Multiple-choice" task, with an accuracy of only approximately 0.20.
* Qwen-2.5-3B has the highest Generation accuracy, at approximately 0.90.
* The "Generation" accuracy is consistently higher than the "Multiple-choice" accuracy for most models.
### Interpretation
The chart demonstrates a clear difference in performance between the various language models on the two task types. Gemini-2.0-Flash consistently outperforms the other models, suggesting it is the most capable model in this comparison. The disparity in accuracy between "Generation" and "Multiple-choice" tasks suggests that these models may be better suited for generative tasks than for selecting from pre-defined options. The low performance of SmalLM2-1.7B on the "Multiple-choice" task could indicate a weakness in its ability to understand and reason about the given options. The secondary label "Dwebi-Llama-8B" under "DeepSeek-R1" suggests a potential relationship or derivation between these two models, possibly indicating that DeepSeek-R1 is built upon or fine-tuned from Dwebi-Llama-8B. The trend of increasing Generation accuracy as you move from left to right suggests a correlation between model complexity/size and performance on this task.