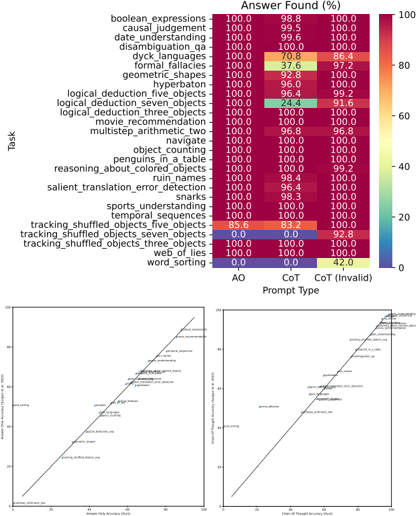
## Heatmap and Scatter Plots: Prompt Type Performance on Various Tasks
### Overview
The image presents a performance analysis of different prompt types on a variety of tasks. It includes a heatmap showing the "Answer Found (%)" for each task across three prompt types: AO, CoT, and CoT (Invalid). Additionally, there are two scatter plots comparing the performance of AO vs. CoT and AO vs. CoT (Invalid).
### Components/Axes
#### Heatmap
* **Title:** Answer Found (%)
* **Y-axis (Task):** Lists various tasks such as boolean expressions, causal judgement, date understanding, disambiguation\_qa, dyck languages, formal fallacies, geometric shapes, hyperbaton, logical\_deduction\_five\_objects, logical\_deduction\_seven\_objects, logical\_deduction\_three\_objects, movie\_recommendation, multistep\_arithmetic\_two, navigate, object\_counting, penguins\_in\_a\_table, reasoning\_about\_colored\_objects, ruin\_names, salient\_translation\_error\_detection, snarks, sports\_understanding, temporal sequences, tracking\_shuffled\_objects\_five\_objects, tracking\_shuffled\_objects\_seven\_objects, tracking\_shuffled\_objects\_three\_objects, web\_of\_lies, word\_sorting.
* **X-axis (Prompt Type):** AO, CoT, CoT (Invalid)
* **Color Scale:** Ranges from dark blue (0%) to dark red (100%), with intermediate colors representing values in between.
#### Scatter Plots
* **Left Scatter Plot:**
* **X-axis:** Answer Only Accuracy (Ours)
* **Y-axis:** Answer Only Accuracy (Kojima et al. 2022)
* **Right Scatter Plot:**
* **X-axis:** Chain of Thought Accuracy (Ours)
* **Y-axis:** Chain of Thought Accuracy (Kojima et al. 2022)
### Detailed Analysis
#### Heatmap Data
The heatmap displays the percentage of correct answers for each task and prompt type.
* **boolean expressions:** AO: 100.0%, CoT: 98.8%, CoT (Invalid): 100.0%
* **causal judgement:** AO: 100.0%, CoT: 99.5%, CoT (Invalid): 100.0%
* **date\_understanding:** AO: 100.0%, CoT: 99.6%, CoT (Invalid): 100.0%
* **disambiguation\_qa:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **dyck languages:** AO: 100.0%, CoT: 70.8%, CoT (Invalid): 86.4%
* **formal fallacies:** AO: 100.0%, CoT: 37.6%, CoT (Invalid): 97.2%
* **geometric\_shapes:** AO: 100.0%, CoT: 92.8%, CoT (Invalid): 100.0%
* **hyperbaton:** AO: 100.0%, CoT: 96.0%, CoT (Invalid): 100.0%
* **logical\_deduction\_five\_objects:** AO: 100.0%, CoT: 96.4%, CoT (Invalid): 99.2%
* **logical\_deduction\_seven\_objects:** AO: 100.0%, CoT: 24.4%, CoT (Invalid): 91.6%
* **logical\_deduction\_three\_objects:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **movie\_recommendation:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **multistep\_arithmetic\_two:** AO: 100.0%, CoT: 96.8%, CoT (Invalid): 96.8%
* **navigate:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **object\_counting:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **penguins\_in\_a\_table:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **reasoning\_about\_colored\_objects:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 99.2%
* **ruin\_names:** AO: 100.0%, CoT: 98.4%, CoT (Invalid): 100.0%
* **salient\_translation\_error\_detection:** AO: 100.0%, CoT: 96.4%, CoT (Invalid): 100.0%
* **snarks:** AO: 100.0%, CoT: 98.3%, CoT (Invalid): 100.0%
* **sports\_understanding:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **temporal\_sequences:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **tracking\_shuffled\_objects\_five\_objects:** AO: 85.6%, CoT: 83.2%, CoT (Invalid): 100.0%
* **tracking\_shuffled\_objects\_seven\_objects:** AO: 0.0%, CoT: 0.0%, CoT (Invalid): 92.8%
* **tracking\_shuffled\_objects\_three\_objects:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **web\_of\_lies:** AO: 100.0%, CoT: 100.0%, CoT (Invalid): 100.0%
* **word\_sorting:** AO: 0.0%, CoT: 0.0%, CoT (Invalid): 42.0%
#### Scatter Plot Data
The scatter plots compare the accuracy of "Ours" (presumably the current study) against "Kojima et al. 2022" for both Answer Only and Chain of Thought approaches. Each point represents a task, but the specific tasks are difficult to read due to the small font size. The diagonal line represents perfect agreement between the two studies.
* **Left Scatter Plot (Answer Only):** The points are clustered relatively close to the diagonal line, suggesting a general agreement between the two studies regarding Answer Only accuracy.
* **Right Scatter Plot (Chain of Thought):** The points are more scattered compared to the left plot, indicating less agreement between the two studies regarding Chain of Thought accuracy. Many points lie above the diagonal, suggesting that the "Ours" method generally outperforms Kojima et al. 2022 in Chain of Thought accuracy.
### Key Observations
* The AO prompt type generally performs very well across most tasks, often achieving 100% accuracy.
* The CoT prompt type shows variable performance, with some tasks achieving high accuracy (e.g., movie\_recommendation) and others showing significantly lower accuracy (e.g., logical\_deduction\_seven\_objects, formal fallacies).
* The CoT (Invalid) prompt type generally performs well, often matching or exceeding the performance of AO. However, it shows lower performance on "word\_sorting" compared to other tasks.
* The "tracking\_shuffled\_objects\_seven\_objects" and "word\_sorting" tasks show particularly poor performance for AO and CoT prompt types.
* The scatter plots indicate a stronger agreement between the current study and Kojima et al. 2022 for Answer Only accuracy compared to Chain of Thought accuracy.
### Interpretation
The data suggests that the choice of prompt type can significantly impact the performance of language models on various tasks. The AO prompt type appears to be a robust baseline, achieving high accuracy across many tasks. However, the CoT prompt type can lead to either improved or degraded performance depending on the specific task. The CoT (Invalid) prompt type seems to offer a good balance, often matching or exceeding the performance of AO while avoiding the significant performance drops observed with CoT on certain tasks.
The poor performance of AO and CoT on "tracking\_shuffled\_objects\_seven\_objects" and "word\_sorting" suggests that these tasks may be particularly challenging for language models, requiring more sophisticated reasoning or problem-solving strategies. The improved performance of CoT (Invalid) on "tracking\_shuffled\_objects\_seven\_objects" and "word_sorting" compared to AO and CoT suggests that the "invalid" chain of thought may be providing some useful information or regularization.
The scatter plots highlight the variability in Chain of Thought performance across different studies, suggesting that the effectiveness of CoT may be sensitive to factors such as model architecture, training data, or prompt engineering. The fact that "Ours" generally outperforms Kojima et al. 2022 in Chain of Thought accuracy suggests that the current study may have employed more effective CoT strategies.