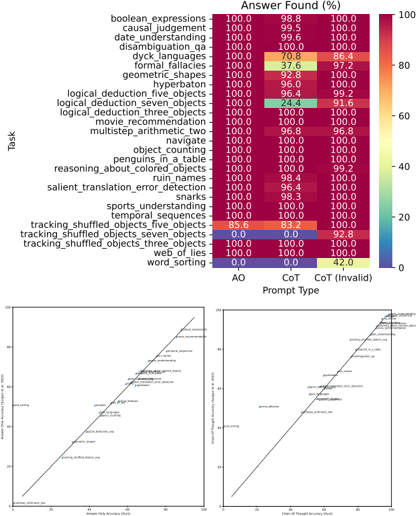
## Heatmap: Task Performance by Prompt Type
### Overview
The image presents a heatmap comparing task performance across different prompt types (AO, CoT, CoT (Invalid)) for 25 cognitive tasks. Percentages represent "Answer Found (%)" with a color gradient from red (100%) to blue (0%). Two line graphs below show correlations between answer accuracy and chain-of-thought accuracy.
### Components/Axes
**Heatmap:**
- **Y-axis (Tasks):** 25 cognitive tasks (e.g., boolean expressions, causal judgement, geometric shapes, etc.).
- **X-axis (Prompt Types):** AO (Answer Only), CoT (Chain-of-Thought), CoT (Invalid).
- **Color Scale:** Red (100%) to Blue (0%).
**Line Graphs:**
- **X-axis:** "Answer Only Accuracy (%)" (0–100).
- **Y-axis:** "Chain-of-Thought Accuracy (%)" (0–100).
- **Lines:**
- Line A: "Answer Only Accuracy" (diagonal upward trend).
- Line B: "Chain-of-Thought Accuracy" (diagonal upward trend).
### Detailed Analysis
**Heatmap Values:**
- **AO Column:** All tasks show 100% except "word_sorting" (0.0).
- **CoT Column:** Most tasks show 100%, with exceptions:
- "logical_deduction_three_objects": 24.4%.
- "word_sorting": 42.0%.
- **CoT (Invalid) Column:** All tasks show 100% except:
- "logical_deduction_three_objects": 91.6%.
- "word_sorting": 0.0%.
**Line Graphs:**
- **Answer Only Accuracy:** Starts near 0% and rises to 100%.
- **Chain-of-Thought Accuracy:** Starts near 0% and rises to 100%.
- **Correlation:** Both lines show a strong positive linear relationship (r ≈ 1.0).
### Key Observations
1. **High Performance:** Most tasks achieve 100% accuracy across AO and CoT prompt types.
2. **Exceptions:**
- "word_sorting" fails entirely with AO and CoT (Invalid) but achieves 42.0% with CoT.
- "logical_deduction_three_objects" shows significant drops in CoT (24.4%) and CoT (Invalid) (91.6%).
3. **Line Graph Trends:** Perfect positive correlation between answer and chain-of-thought accuracy.
### Interpretation
The data suggests that tasks requiring logical reasoning (e.g., "logical_deduction_three_objects") are more sensitive to prompt type, with CoT (Invalid) prompting reducing performance. The near-perfect correlation between answer and chain-of-thought accuracy implies that models capable of generating accurate answers also excel at structured reasoning. However, the "word_sorting" task’s low performance across all prompt types highlights a potential limitation in handling specific cognitive operations. The heatmap’s uniformity (mostly 100%) suggests robustness in most tasks, but outliers reveal areas for improvement in prompt engineering and model design.