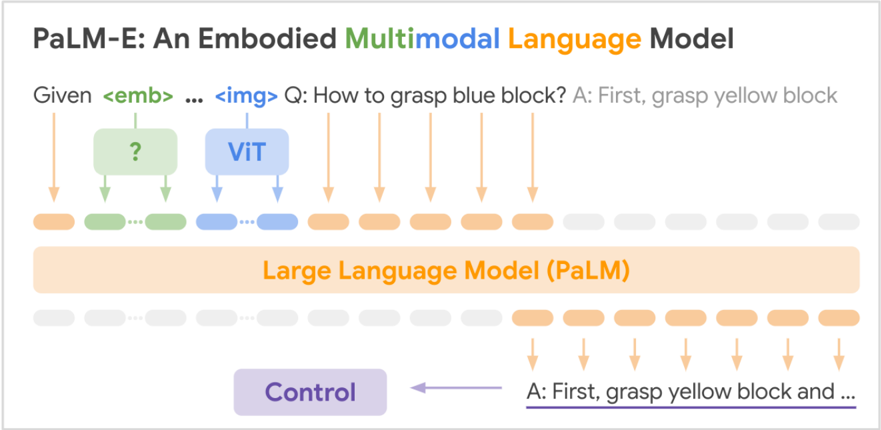
## Diagram: PaLM-E Model Architecture
### Overview
The image is a diagram illustrating the architecture of the PaLM-E (Embodied Multimodal Language Model). It shows the flow of information from input (embedding and image) through the model, including the use of ViT (Vision Transformer) and a Large Language Model (PaLM), and finally to the output control signal.
### Components/Axes
* **Title:** PaLM-E: An Embodied Multimodal Language Model
* **Input:**
* Given `<emb>` ... `<img>` Q: How to grasp blue block? A: First, grasp yellow block
* Embedding represented by a green box with a question mark inside.
* Image represented by a blue box labeled "ViT".
* **Processing:**
* Large Language Model (PaLM) represented by a large orange box.
* **Output:**
* Control represented by a purple box.
* A: First, grasp yellow block and ... (underlined)
* **Arrows:** Arrows indicate the flow of information.
* Orange arrows connect the input text to the Large Language Model.
* Green arrows connect the embedding to the Large Language Model.
* Blue arrows connect the ViT to the Large Language Model.
* Purple arrow connects the output to the Control.
### Detailed Analysis
The diagram shows the following flow:
1. **Input:** The input consists of text (Given `<emb>` ... `<img>` Q: How to grasp blue block? A: First, grasp yellow block), an embedding (represented by a green box with a question mark), and an image (processed by ViT, represented by a blue box).
2. **Processing:** The embedding and ViT output are fed into the Large Language Model (PaLM). The input text is also fed into the Large Language Model.
3. **Output:** The Large Language Model generates a control signal, which is used to control the robot. The output text is A: First, grasp yellow block and ...
The diagram uses color-coding to distinguish between different types of information:
* Orange: Text
* Green: Embedding
* Blue: Image (ViT)
* Purple: Control
### Key Observations
* The PaLM-E model takes multimodal input (text, embedding, and image).
* The model uses ViT to process the image.
* The model uses a Large Language Model (PaLM) to generate a control signal.
* The control signal is used to control the robot.
### Interpretation
The diagram illustrates how the PaLM-E model combines information from different modalities (text, embedding, and image) to generate a control signal for a robot. The model uses ViT to process the image and a Large Language Model (PaLM) to generate the control signal. The diagram suggests that the PaLM-E model is capable of understanding and responding to complex instructions that involve both language and vision. The example question "How to grasp blue block?" and the answer "A: First, grasp yellow block..." indicate that the model can reason about objects and actions in the real world.