\n
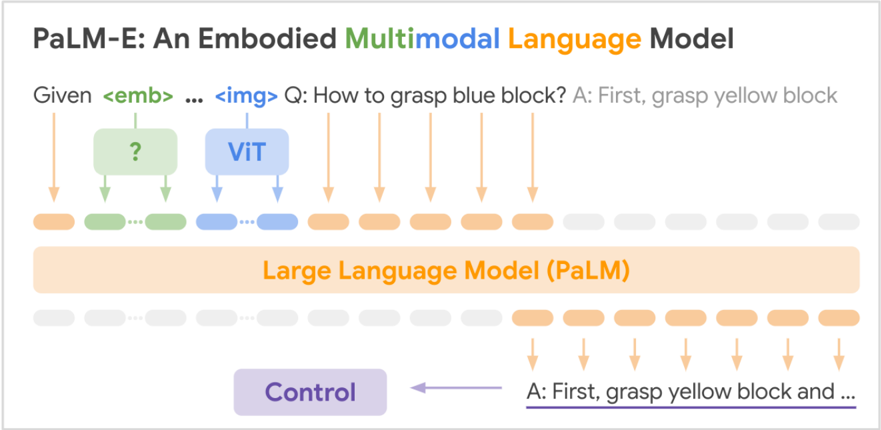
## Diagram: PaLM-E Architecture
### Overview
The image depicts a diagram illustrating the architecture of PaLM-E (Pathways Language Model - Embodied), a multimodal language model. The diagram shows the flow of information from input (image and text) through various components to generate an output (textual response). It highlights the integration of visual information processed by a Vision Transformer (ViT) with a Large Language Model (PaLM).
### Components/Axes
The diagram consists of three main sections: Input, Processing, and Output.
* **Input:** Includes `<emb>`, `img`, and a question "Q: How to grasp blue block?". The answer "A: First, grasp yellow block" is also shown as an initial output.
* **Processing:** This section is divided into two layers. The upper layer represents the visual processing stage, utilizing a Vision Transformer (ViT) and an unknown component represented by a question mark "?". The lower layer represents the Large Language Model (PaLM).
* **Output:** The final output is "A: First, grasp yellow block and ...", connected to a "Control" component.
* **Arrows:** Arrows indicate the flow of information between components.
* **Color Coding:**
* Orange: Represents the visual processing pathway.
* Light Orange: Represents the intermediate processing steps within the LLM.
* Purple: Represents the control/output pathway.
* Green: Represents the initial input embedding.
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. **Input:** The system receives an embedding (`<emb>`) and an image (`img`). The question posed is "Q: How to grasp blue block?". An initial answer "A: First, grasp yellow block" is provided.
2. **Visual Processing:** The image is processed by a Vision Transformer (ViT). An additional component, marked with a question mark, also contributes to the visual processing. Both components feed into the Large Language Model (PaLM).
3. **Language Processing:** The Large Language Model (PaLM) processes the visual information from the ViT and the embedding, generating a textual response.
4. **Output:** The final output, "A: First, grasp yellow block and ...", is sent to a "Control" component.
The diagram does not provide numerical data or specific values. It is a conceptual representation of the model's architecture.
### Key Observations
* The diagram emphasizes the multimodal nature of PaLM-E, integrating visual and textual information.
* The Vision Transformer (ViT) is a key component for processing visual input.
* The Large Language Model (PaLM) serves as the central processing unit, combining visual and textual information to generate responses.
* The "Control" component suggests a mechanism for regulating or refining the output.
* The question and answer pair suggest a task-oriented application, likely related to robotics or embodied AI.
### Interpretation
The diagram illustrates a system designed to understand and respond to questions about visual scenes. The integration of a Vision Transformer (ViT) with a Large Language Model (PaLM) allows the model to "see" and "understand" the environment, enabling it to generate appropriate actions or responses. The "Control" component suggests a layer of decision-making or refinement, ensuring the output is aligned with the desired behavior. The example question and answer ("How to grasp blue block?" and "First, grasp yellow block") indicate the model is capable of reasoning about object manipulation and providing instructions for completing tasks. The question mark in the visual processing stage suggests that the architecture may include additional, unspecified components or processing steps. The diagram highlights the potential of multimodal language models for enabling robots and AI agents to interact with the physical world in a more intelligent and effective manner.