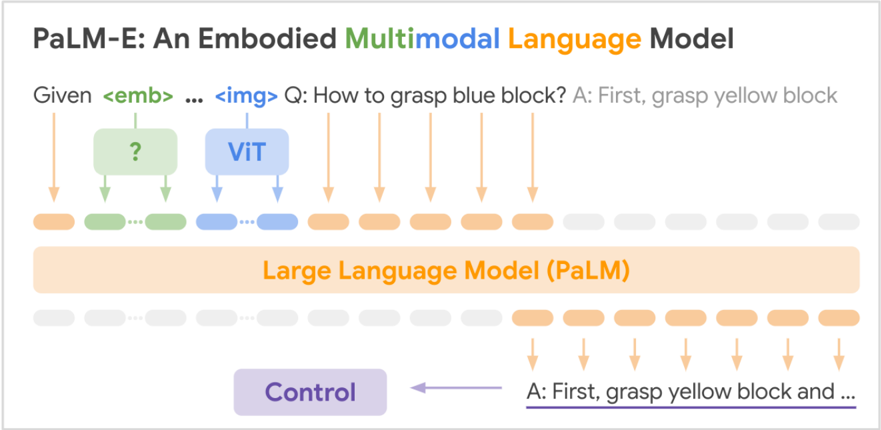
## Diagram: PaLM-E System Architecture
### Overview
This image is a technical diagram illustrating the architecture and data flow of "PaLM-E: An Embodied Multimodal Language Model." It depicts how multimodal inputs (text and images) are processed by a large language model to generate control commands for an embodied agent.
### Components/Axes
The diagram is structured as a flowchart with the following labeled components and text elements, from top to bottom:
1. **Title:** "PaLM-E: An Embodied **Multimodal** **Language Model**"
* The words "Multimodal" and "Language Model" are in distinct colors (green and orange, respectively).
2. **Input Sequence:** A line of text representing a prompt: "Given `<emb>` ... `<img>` Q: How to grasp blue block? A: First, grasp yellow block"
* `<emb>` is highlighted in a green box.
* `<img>` is highlighted in a blue box.
3. **Processing Modules (Middle Layer):**
* A green box with a question mark `?` inside. Arrows point from the `<emb>` token to this box and from this box down to the token sequence.
* A blue box labeled "ViT" (Vision Transformer). Arrows point from the `<img>` token to this box and from this box down to the token sequence.
4. **Token Sequence:** A horizontal row of rounded rectangles representing tokens.
* The first two tokens are green (corresponding to the `<emb>` path).
* The next two tokens are blue (corresponding to the `<img>`/ViT path).
* The following six tokens are orange.
* The final four tokens are light grey.
5. **Core Model:** A large, wide orange rectangle spanning the width of the token sequence, labeled: "Large Language Model (PaLM)".
6. **Output Token Sequence:** A second horizontal row of tokens below the LLM block.
* The first eight tokens are light grey.
* The final six tokens are orange.
7. **Output Text & Control:**
* Text below the final orange tokens: "A: First, grasp yellow block and ..."
* A purple arrow points from this text to a purple box labeled "Control".
### Detailed Analysis
The diagram illustrates a specific inference process:
1. **Input Encoding:** The system receives a multimodal prompt. The text embedding (`<emb>`) is processed by an unspecified module (green `?` box), and the image (`<img>`) is processed by a Vision Transformer (ViT). Their outputs are converted into a sequence of continuous embedding vectors (the green and blue tokens).
2. **Language Model Processing:** These embedding vectors are concatenated with the embedding vectors of the text tokens (the orange tokens representing the question and partial answer) and fed into the core Large Language Model (PaLM).
3. **Autoregressive Generation:** The LLM processes the entire sequence and generates new tokens autoregressively. The output sequence (bottom row) shows the model continuing the answer: "A: First, grasp yellow block and ...".
4. **Embodied Action:** The generated text output is not the final endpoint. It is directed (via the purple arrow) to a "Control" module, indicating that the language model's output is used to generate low-level control commands for a physical agent (e.g., a robot) to execute the described task.
### Key Observations
* **Multimodal Fusion:** The architecture shows "early fusion," where inputs from different modalities (text embeddings, image features) are embedded into a common sequence space before being processed by the unified LLM.
* **Embodied Focus:** The final output is not just text but a command to a "Control" system, highlighting the model's purpose for embodied AI tasks (robotics).
* **Color-Coding:** Colors are used systematically to trace data flow: green for text embeddings, blue for image embeddings, orange for LLM-processed text tokens, and purple for the final control output.
* **Partial Generation:** The output text ends with "and ...", indicating the generation is truncated in this diagram for illustration.
### Interpretation
This diagram explains the core innovation of PaLM-E: treating a powerful, pre-trained large language model (PaLM) as a central "brain" that can directly process and reason over continuous sensor data (like images) by embedding it into the same sequence as text. The model isn't just describing images; it's using visual information in conjunction with a textual goal ("grasp blue block") to formulate a step-by-step plan ("First, grasp yellow block") that is then translated into actionable control signals. This represents a shift from modular pipelines (separate vision, planning, and control systems) to a more integrated, end-to-end approach where a single multimodal model handles perception, reasoning, and action generation. The "?" box suggests the text embedding module might be a trainable or unspecified component, while the ViT is a standard, likely pre-trained, vision encoder.