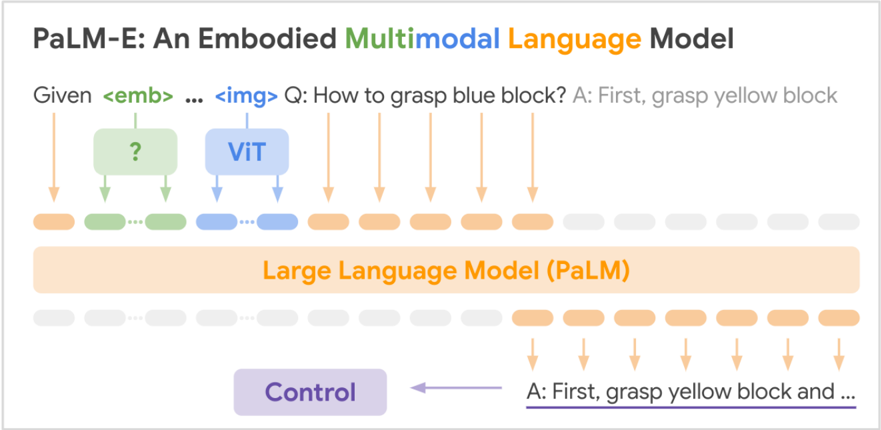
## Diagram: PaLM-E Architecture Overview
### Overview
The diagram illustrates the architecture of PaLM-E, an embodied multimodal language model that integrates visual and language processing. It demonstrates how the system processes inputs (embodied context and images) to generate actionable responses through a large language model (PaLM) with control mechanisms.
### Components/Axes
- **Header**:
- Title: "PaLM-E: An Embodied Multimodal Language Model"
- Subtitle: "Given <emb> ... <img> Q: How to grasp blue block? A: First, grasp yellow block"
- **Main Diagram**:
- **Input Components**:
- `<emb>` (green): Embodied context (e.g., robot state).
- `<img>` (blue): Visual input (e.g., camera feed).
- **Processing**:
- **ViT (Vision Transformer)**: Blue block with arrows pointing to the question/answer.
- **Question/Answer**: Textual query ("How to grasp blue block?") and response ("First, grasp yellow block").
- **Control Mechanism**: Purple block labeled "Control" directing output.
- **Footer**:
- "Large Language Model (PaLM)" in orange, spanning the width of the diagram.
### Detailed Analysis
- **Textual Elements**:
- All labels are explicitly annotated: `<emb>`, `<img>`, `ViT`, `Q: ...`, `A: ...`, `Control`, and `PaLM`.
- Arrows indicate data flow:
- `<emb>` and `<img>` feed into ViT.
- ViT processes inputs to generate the question/answer.
- Control directs the final output to PaLM.
- **Color Coding**:
- Green (`<emb>`), blue (`<img>`, `ViT`), orange (`PaLM`), and purple (`Control`).
- Legend colors match component colors exactly.
### Key Observations
1. **Modular Design**: The system separates embodied context (`<emb>`), visual input (`<img>`), and language processing (`PaLM`).
2. **Sequential Reasoning**: The answer ("First, grasp yellow block") implies step-by-step task decomposition.
3. **Control Integration**: The "Control" block acts as a mediator between ViT and PaLM, ensuring alignment between visual and language outputs.
### Interpretation
The diagram highlights PaLM-E's multimodal integration:
- **Vision-Language Synergy**: ViT processes visual data (`<img>`) while `<emb>` provides embodied context, enabling grounded language understanding.
- **Task Execution**: The model generates actionable instructions (e.g., "grasp yellow block") by combining visual perception and language reasoning.
- **Control Mechanism**: Ensures the final output adheres to task constraints, suggesting a feedback loop for robustness.
This architecture demonstrates how embodied AI systems can bridge perception (vision/embodiment) and action (language-driven instructions) for real-world tasks.