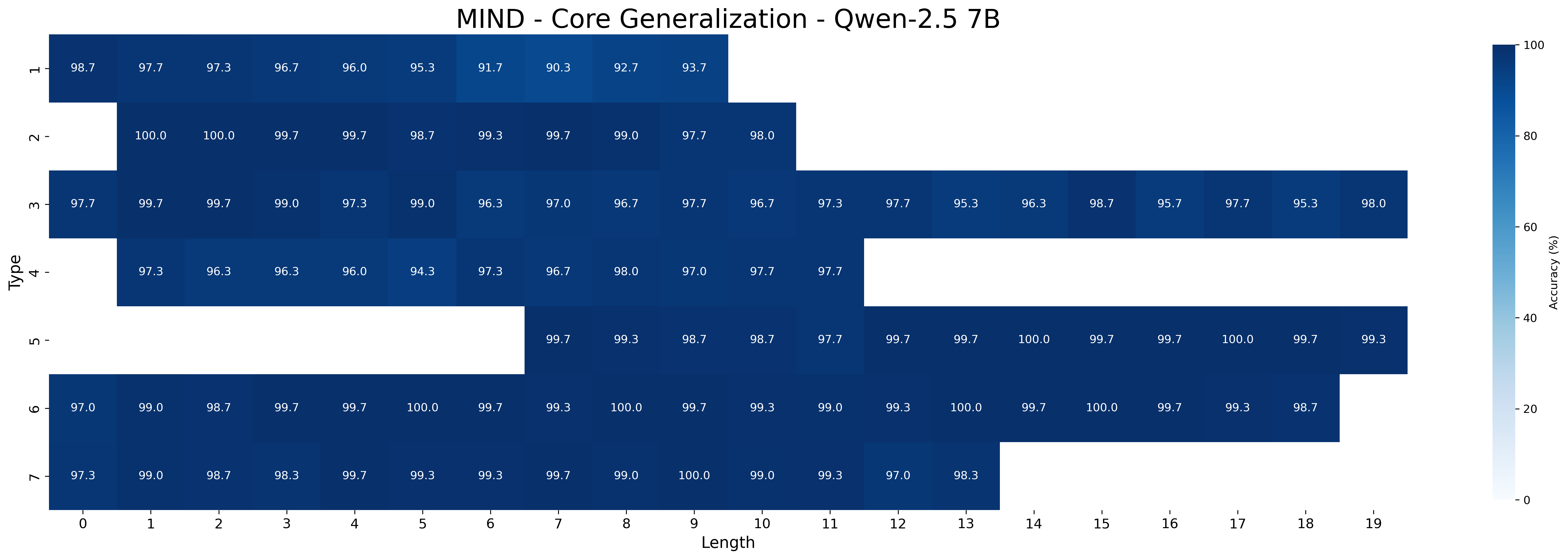
## Heatmap: MIND - Core Generalization - Qwen-2.5 7B
### Overview
This image is a heatmap visualizing the core generalization performance of the MIND model (Qwen-2.5 7B) across different types and lengths. The heatmap displays accuracy percentages, with darker blue shades indicating higher accuracy and lighter shades indicating lower accuracy. The y-axis represents "Type" (ranging from 1 to 7), and the x-axis represents "Length" (ranging from 0 to 19).
### Components/Axes
* **Title:** MIND - Core Generalization - Qwen-2.5 7B
* **X-axis:** Length (0 to 19)
* **Y-axis:** Type (1 to 7)
* **Colorbar (right side):** Accuracy (%) ranging from 0 to 100, with a gradient from light blue (0%) to dark blue (100%).
### Detailed Analysis
The heatmap presents accuracy values for each combination of "Type" and "Length." Here's a breakdown of the accuracy values for each type across different lengths:
* **Type 1:**
* Length 0: 98.7%
* Length 1: 97.7%
* Length 2: 97.3%
* Length 3: 96.7%
* Length 4: 96.0%
* Length 5: 95.3%
* Length 6: 91.7%
* Length 7: 90.3%
* Length 8: 92.7%
* Length 9: 93.7%
* **Type 2:**
* Length 0: 100.0%
* Length 1: 100.0%
* Length 2: 99.7%
* Length 3: 99.7%
* Length 4: 98.7%
* Length 5: 99.3%
* Length 6: 99.7%
* Length 7: 99.0%
* Length 8: 97.7%
* Length 9: 98.0%
* **Type 3:**
* Length 0: 97.7%
* Length 1: 99.7%
* Length 2: 99.7%
* Length 3: 99.0%
* Length 4: 97.3%
* Length 5: 99.0%
* Length 6: 96.3%
* Length 7: 97.0%
* Length 8: 96.7%
* Length 9: 97.7%
* Length 10: 96.7%
* Length 11: 97.3%
* Length 12: 97.7%
* Length 13: 95.3%
* Length 14: 96.3%
* Length 15: 98.7%
* Length 16: 95.7%
* Length 17: 97.7%
* Length 18: 95.3%
* Length 19: 98.0%
* **Type 4:**
* Length 0: 97.3%
* Length 1: 96.3%
* Length 2: 96.3%
* Length 3: 96.0%
* Length 4: 94.3%
* Length 5: 97.3%
* Length 6: 96.7%
* Length 7: 98.0%
* Length 8: 97.0%
* Length 9: 97.7%
* **Type 5:**
* Length 7: 99.7%
* Length 8: 99.3%
* Length 9: 98.7%
* Length 10: 98.7%
* Length 11: 97.7%
* Length 12: 99.7%
* Length 13: 99.7%
* Length 14: 100.0%
* Length 15: 99.7%
* Length 16: 99.7%
* Length 17: 100.0%
* Length 18: 99.7%
* Length 19: 99.3%
* **Type 6:**
* Length 0: 97.0%
* Length 1: 99.0%
* Length 2: 98.7%
* Length 3: 99.7%
* Length 4: 99.7%
* Length 5: 100.0%
* Length 6: 99.7%
* Length 7: 99.3%
* Length 8: 100.0%
* Length 9: 99.7%
* Length 10: 99.3%
* Length 11: 99.0%
* Length 12: 99.3%
* Length 13: 100.0%
* Length 14: 99.7%
* Length 15: 100.0%
* Length 16: 99.7%
* Length 17: 99.3%
* Length 18: 98.7%
* **Type 7:**
* Length 0: 97.3%
* Length 1: 99.0%
* Length 2: 98.7%
* Length 3: 98.3%
* Length 4: 99.7%
* Length 5: 99.3%
* Length 6: 99.3%
* Length 7: 99.7%
* Length 8: 99.0%
* Length 9: 100.0%
* Length 10: 99.0%
* Length 11: 99.3%
* Length 12: 97.0%
* Length 13: 98.3%
### Key Observations
* Types 2, 5, 6, and 7 generally exhibit higher accuracy compared to Types 1, 3, and 4.
* Accuracy tends to vary more for shorter lengths (0-5) and stabilizes or increases for longer lengths, especially for Types 5, 6, and 7.
* Type 1 shows a decreasing trend in accuracy as length increases from 0 to 7, then a slight increase.
* Type 4 has the lowest accuracy values overall, especially for lengths 3 and 4.
### Interpretation
The heatmap provides insights into how the MIND model's core generalization ability varies across different types and lengths of input. The higher accuracy values for Types 2, 5, 6, and 7 suggest that the model performs better on these specific types, potentially due to the nature of the data or tasks associated with these types. The variability in accuracy for shorter lengths could indicate that the model requires a certain amount of context to perform optimally. The lower accuracy for Type 1 as length increases to 7, suggests that the model struggles with longer sequences of this type. The consistently high accuracy for Types 5, 6, and 7 across longer lengths indicates robust generalization capabilities for these types. Type 4's lower accuracy suggests potential challenges in handling this specific type of input. Overall, the heatmap highlights the model's strengths and weaknesses in generalizing across different types and lengths, which can inform future model improvements and targeted applications.