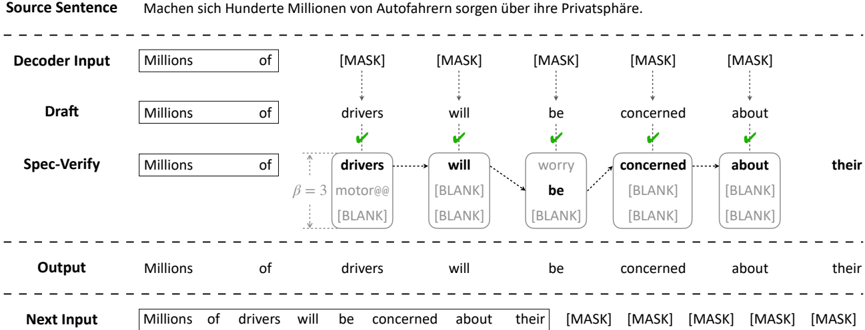
## Diagram: Machine Translation/Generation Process Flow
### Overview
The diagram illustrates a multi-stage text generation process, likely from a machine translation or language model. It shows the progression from a source sentence in German through decoding, drafting, specification verification, and output generation. Key elements include masked tokens ([MASK]), blank placeholders ([BLANK]), and verification checkmarks.
### Components/Axes
1. **Source Sentence**:
- Text: "Machen sich Hunderte Millionen von Autofahrern sorgen über ihre Privatsphäre."
- Translation: "Hundreds of millions of drivers are concerned about their privacy."
2. **Decoder Input**:
- Text: "Millions of [MASK] [MASK] [MASK] [MASK] [MASK]"
3. **Draft**:
- Text: "Millions of drivers will be concerned about their"
4. **Spec-Verify**:
- Text: "Millions of drivers will worry be concerned about their"
- Includes β=3 notation (likely a model parameter, e.g., beam width).
5. **Output**:
- Text: "Millions of drivers will be concerned about their"
6. **Next Input**:
- Text: "Millions of drivers will be concerned about their [MASK] [MASK] [MASK] [MASK] [MASK]"
### Detailed Analysis
- **Source Sentence**: The input is a German sentence about driver privacy concerns.
- **Decoder Input**: The model begins with "Millions of" followed by five [MASK] tokens, indicating positions to be filled.
- **Draft**: The model predicts "drivers will be concerned about their" with checkmarks confirming correct word choices for "drivers," "will," "be," "concerned," and "about."
- **Spec-Verify**:
- Predicts "worry" for the first [BLANK] but leaves subsequent [BLANK]s unresolved.
- β=3 suggests a parameter influencing the model's confidence or hypothesis selection.
- **Output**: Finalizes the sentence with verified words, retaining "their" as unresolved.
- **Next Input**: Continues the output with five [MASK] tokens, implying iterative refinement.
### Key Observations
- **Checkmarks**: Indicate successful predictions at specific positions (e.g., "drivers," "will," "be").
- **BLANKs**: Highlight unresolved tokens requiring further verification or refinement.
- **β=3**: Likely a tunable parameter affecting the model's decision-making process (e.g., beam search width).
- **Iterative Flow**: The process loops back to "Next Input," suggesting ongoing optimization.
### Interpretation
The diagram demonstrates a stepwise text generation pipeline where the model balances confidence (via checkmarks) and uncertainty (via [BLANK]s). The Spec-Verify stage acts as a quality control step, refining predictions before finalizing the output. The presence of β=3 implies the model uses a constrained search space (e.g., top-3 hypotheses) to balance accuracy and efficiency. The unresolved [MASK]s in "Next Input" suggest the process is iterative, with future steps addressing remaining ambiguities. This workflow highlights the interplay between automated generation and human-like verification in natural language processing systems.