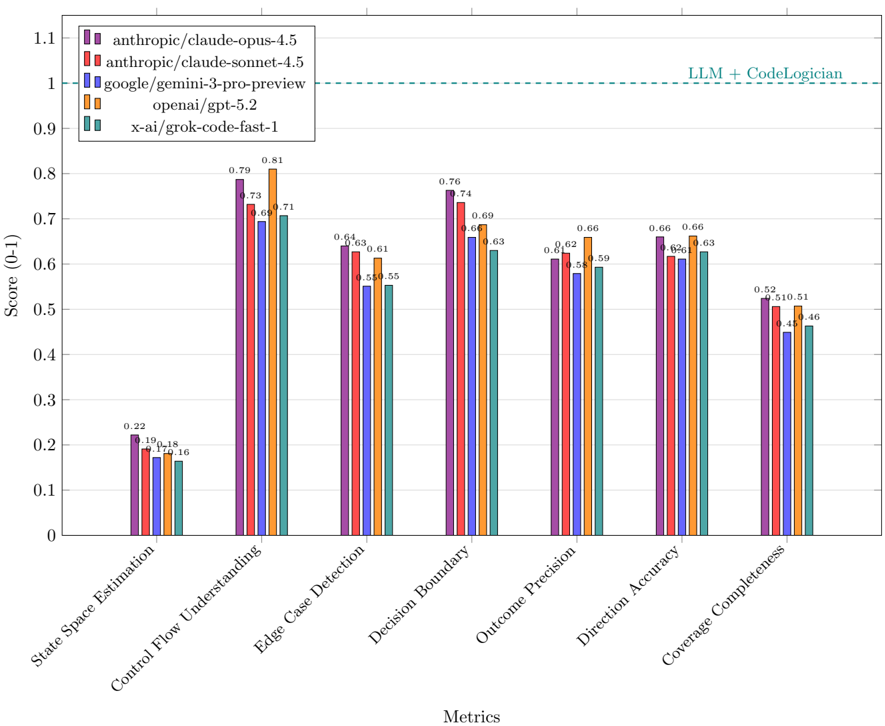
## Bar Chart: LLM Performance on Code-Related Metrics
### Overview
The image is a bar chart comparing the performance of five different Large Language Models (LLMs) across six code-related metrics. The chart displays the scores (ranging from 0 to 1) achieved by each model on each metric. A horizontal line indicates a baseline performance level labeled "LLM + CodeLogician".
### Components/Axes
* **X-axis:** Metrics: State Space Estimation, Control Flow Understanding, Edge Case Detection, Decision Boundary, Outcome Precision, Direction Accuracy, Coverage Completeness.
* **Y-axis:** Score (0-1), with tick marks at intervals of 0.1 from 0 to 1.1.
* **Legend (top-left):**
* Purple: anthropic/claude-opus-4.5
* Red: anthropic/claude-sonnet-4.5
* Blue: google/gemini-3-pro-preview
* Orange: openai/gpt-5.2
* Teal: x-ai/grok-code-fast-1
* **Horizontal Line:** A dashed teal line at approximately y=1.0, labeled "LLM + CodeLogician".
### Detailed Analysis
**1. State Space Estimation:**
* anthropic/claude-opus-4.5 (Purple): 0.22
* anthropic/claude-sonnet-4.5 (Red): 0.19
* google/gemini-3-pro-preview (Blue): 0.18
* openai/gpt-5.2 (Orange): 0.17
* x-ai/grok-code-fast-1 (Teal): 0.16
**2. Control Flow Understanding:**
* anthropic/claude-opus-4.5 (Purple): 0.79
* anthropic/claude-sonnet-4.5 (Red): 0.73
* google/gemini-3-pro-preview (Blue): 0.69
* openai/gpt-5.2 (Orange): 0.81
* x-ai/grok-code-fast-1 (Teal): 0.71
**3. Edge Case Detection:**
* anthropic/claude-opus-4.5 (Purple): 0.64
* anthropic/claude-sonnet-4.5 (Red): 0.63
* google/gemini-3-pro-preview (Blue): 0.61
* openai/gpt-5.2 (Orange): 0.58
* x-ai/grok-code-fast-1 (Teal): 0.55
**4. Decision Boundary:**
* anthropic/claude-opus-4.5 (Purple): 0.76
* anthropic/claude-sonnet-4.5 (Red): 0.69
* google/gemini-3-pro-preview (Blue): 0.66
* openai/gpt-5.2 (Orange): 0.74
* x-ai/grok-code-fast-1 (Teal): 0.63
**5. Outcome Precision:**
* anthropic/claude-opus-4.5 (Purple): 0.66
* anthropic/claude-sonnet-4.5 (Red): 0.62
* google/gemini-3-pro-preview (Blue): 0.58
* openai/gpt-5.2 (Orange): 0.66
* x-ai/grok-code-fast-1 (Teal): 0.59
**6. Direction Accuracy:**
* anthropic/claude-opus-4.5 (Purple): 0.66
* anthropic/claude-sonnet-4.5 (Red): 0.66
* google/gemini-3-pro-preview (Blue): 0.62
* openai/gpt-5.2 (Orange): 0.61
* x-ai/grok-code-fast-1 (Teal): 0.63
**7. Coverage Completeness:**
* anthropic/claude-opus-4.5 (Purple): 0.52
* anthropic/claude-sonnet-4.5 (Red): 0.45
* google/gemini-3-pro-preview (Blue): 0.44
* openai/gpt-5.2 (Orange): 0.51
* x-ai/grok-code-fast-1 (Teal): 0.46
### Key Observations
* The "State Space Estimation" metric shows the lowest scores across all models.
* "Control Flow Understanding" and "Decision Boundary" generally have higher scores compared to other metrics.
* openai/gpt-5.2 (Orange) achieves the highest score in "Control Flow Understanding" with a value of 0.81.
* anthropic/claude-opus-4.5 (Purple) generally performs well across all metrics.
* None of the models reach the "LLM + CodeLogician" baseline (1.0) on any metric.
### Interpretation
The bar chart provides a comparative analysis of the performance of different LLMs on specific code-related tasks. The low scores in "State Space Estimation" suggest that this is a challenging area for these models. The higher scores in "Control Flow Understanding" and "Decision Boundary" indicate relative strengths in these areas. The fact that no model reaches the "LLM + CodeLogician" baseline suggests that there is still room for improvement in these LLMs' coding abilities. The performance differences between the models highlight the varying strengths and weaknesses of each architecture.