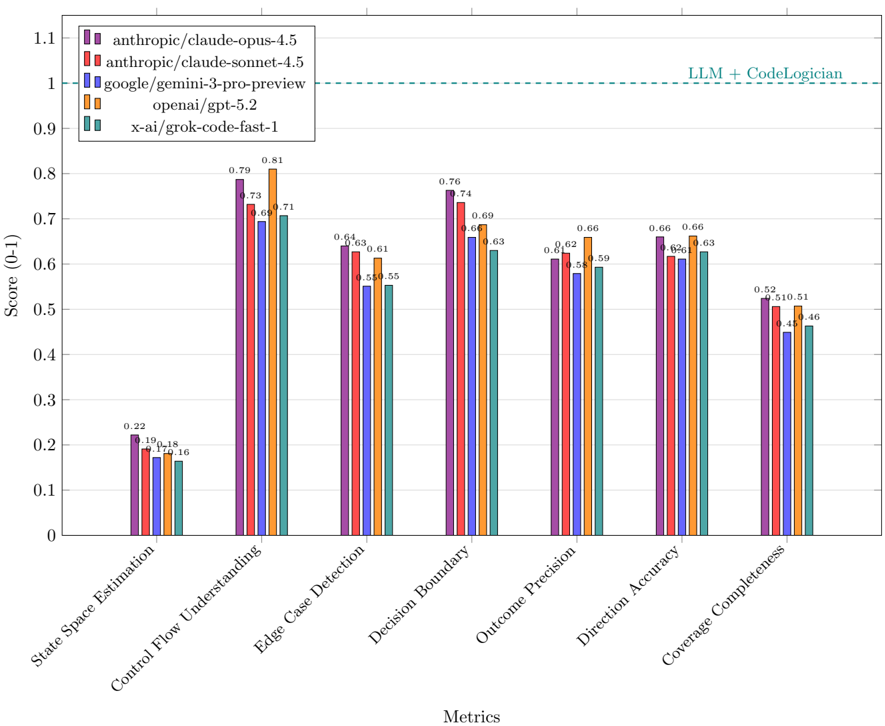
## Bar Chart: Model Performance Across Technical Metrics
### Overview
The chart compares the performance of five AI models (anthropic/claude-opus-4.5, anthropic/claude-sonnet-4.5, google/gemini-3-pro-preview, openai/gpt-5.2, x-ai/grok-code-fast-1) across seven technical metrics. Scores range from 0 to 1.1, with a dashed reference line at 1.0 labeled "LLM + CodeLogician." The chart uses color-coded bars to represent each model's performance.
### Components/Axes
- **X-axis (Metrics)**: State Space Estimation, Control Flow Understanding, Edge Case Detection, Decision Boundary, Outcome Precision, Direction Accuracy, Coverage Completeness.
- **Y-axis (Score)**: 0 to 1.1, with increments of 0.1.
- **Legend**: Located in the top-left, mapping colors to models:
- Purple: anthropic/claude-opus-4.5
- Red: anthropic/claude-sonnet-4.5
- Blue: google/gemini-3-pro-preview
- Orange: openai/gpt-5.2
- Teal: x-ai/grok-code-fast-1
- **Dashed Line**: Horizontal line at 1.0 (LLM + CodeLogician benchmark).
### Detailed Analysis
1. **State Space Estimation**:
- anthropic/claude-opus-4.5: ~0.22
- anthropic/claude-sonnet-4.5: ~0.19
- google/gemini-3-pro-preview: ~0.18
- openai/gpt-5.2: ~0.18
- x-ai/grok-code-fast-1: ~0.16
2. **Control Flow Understanding**:
- anthropic/claude-opus-4.5: ~0.79
- anthropic/claude-sonnet-4.5: ~0.73
- google/gemini-3-pro-preview: ~0.71
- openai/gpt-5.2: ~0.81
- x-ai/grok-code-fast-1: ~0.73
3. **Edge Case Detection**:
- anthropic/claude-opus-4.5: ~0.63
- anthropic/claude-sonnet-4.5: ~0.61
- google/gemini-3-pro-preview: ~0.55
- openai/gpt-5.2: ~0.64
- x-ai/grok-code-fast-1: ~0.55
4. **Decision Boundary**:
- anthropic/claude-opus-4.5: ~0.76
- anthropic/claude-sonnet-4.5: ~0.69
- google/gemini-3-pro-preview: ~0.66
- openai/gpt-5.2: ~0.63
- x-ai/grok-code-fast-1: ~0.63
5. **Outcome Precision**:
- anthropic/claude-opus-4.5: ~0.62
- anthropic/claude-sonnet-4.5: ~0.61
- google/gemini-3-pro-preview: ~0.58
- openai/gpt-5.2: ~0.66
- x-ai/grok-code-fast-1: ~0.59
6. **Direction Accuracy**:
- anthropic/claude-opus-4.5: ~0.66
- anthropic/claude-sonnet-4.5: ~0.62
- google/gemini-3-pro-preview: ~0.61
- openai/gpt-5.2: ~0.63
- x-ai/grok-code-fast-1: ~0.61
7. **Coverage Completeness**:
- anthropic/claude-opus-4.5: ~0.52
- anthropic/claude-sonnet-4.5: ~0.51
- google/gemini-3-pro-preview: ~0.45
- openai/gpt-5.2: ~0.51
- x-ai/grok-code-fast-1: ~0.46
### Key Observations
- **Highest Scores**:
- **Control Flow Understanding**: openai/gpt-5.2 (0.81) and anthropic/claude-opus-4.5 (0.79) lead.
- **Edge Case Detection**: anthropic/claude-opus-4.5 (0.63) and openai/gpt-5.2 (0.64) perform best.
- **Lowest Scores**:
- **State Space Estimation**: x-ai/grok-code-fast-1 (0.16) and google/gemini-3-pro-preview (0.18) lag.
- **Benchmark Comparison**: All models fall below the "LLM + CodeLogician" benchmark (1.0), with the closest being openai/gpt-5.2 in Control Flow Understanding (0.81).
### Interpretation
The data reveals significant variability in model performance across metrics. While anthropic/claude-opus-4.5 and openai/gpt-5.2 consistently outperform others in critical areas like Control Flow Understanding and Edge Case Detection, no model reaches the "LLM + CodeLogician" benchmark. This suggests that combining models (e.g., LLM + CodeLogician) could yield superior results, though the chart does not explicitly test such combinations. The x-ai/grok-code-fast-1 model underperforms in most metrics, indicating potential limitations in its design or training data. The dashed line at 1.0 serves as a critical reference point, highlighting the gap between current models and the idealized performance threshold.