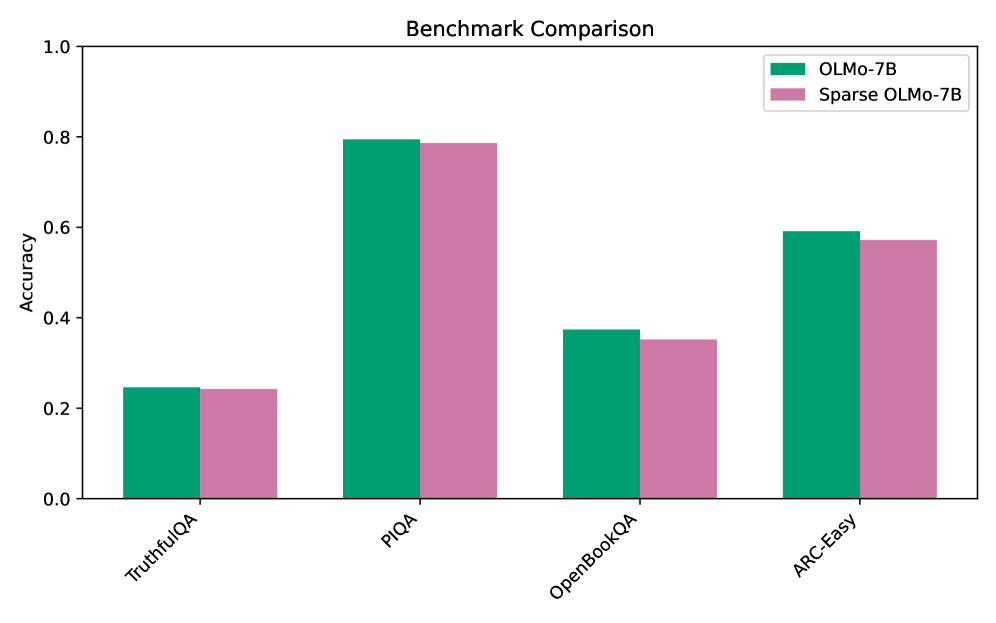
## Bar Chart: Benchmark Comparison
### Overview
The image is a grouped bar chart titled "Benchmark Comparison." It compares the accuracy of two models, "OLMo-7B" and "Sparse OLMo-7B," across four different benchmark datasets. The chart uses a vertical bar format with a clear legend and labeled axes.
### Components/Axes
* **Title:** "Benchmark Comparison" (centered at the top).
* **Y-Axis:** Labeled "Accuracy." The scale runs from 0.0 to 1.0, with major tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **X-Axis:** Lists four benchmark categories. The labels are rotated approximately 45 degrees for readability. From left to right: "TruthfulQA", "PIQA", "OpenBookQA", "ARC-Easy".
* **Legend:** Located in the top-right corner of the plot area. It defines the two data series:
* A teal/green square labeled "OLMo-7B".
* A mauve/pink square labeled "Sparse OLMo-7B".
### Detailed Analysis
The chart presents accuracy scores for two models on four tasks. For each benchmark, the "OLMo-7B" bar (teal) is positioned to the left of the "Sparse OLMo-7B" bar (mauve).
**1. TruthfulQA**
* **Trend:** Both models show the lowest performance on this benchmark compared to the others.
* **Data Points:**
* OLMo-7B: Accuracy is approximately **0.24**.
* Sparse OLMo-7B: Accuracy is approximately **0.24**. The bars appear nearly identical in height.
**2. PIQA**
* **Trend:** This benchmark yields the highest accuracy scores for both models.
* **Data Points:**
* OLMo-7B: Accuracy is approximately **0.80**.
* Sparse OLMo-7B: Accuracy is approximately **0.79**. The sparse model's bar is marginally shorter.
**3. OpenBookQA**
* **Trend:** Performance is moderate, lower than PIQA and ARC-Easy but higher than TruthfulQA.
* **Data Points:**
* OLMo-7B: Accuracy is approximately **0.37**.
* Sparse OLMo-7B: Accuracy is approximately **0.35**. A small but visible gap exists, with the sparse model scoring lower.
**4. ARC-Easy**
* **Trend:** The second-highest performing benchmark for both models.
* **Data Points:**
* OLMo-7B: Accuracy is approximately **0.59**.
* Sparse OLMo-7B: Accuracy is approximately **0.57**. Again, the sparse model shows a slight decrease.
### Key Observations
* **Consistent Performance Gap:** Across all four benchmarks, the "Sparse OLMo-7B" model consistently achieves a slightly lower accuracy score than the standard "OLMo-7B" model. The difference is small but visually apparent in three of the four categories (PIQA, OpenBookQA, ARC-Easy).
* **Benchmark Difficulty Hierarchy:** The relative difficulty of the benchmarks is consistent for both models. From easiest to hardest (highest to lowest accuracy): PIQA > ARC-Easy > OpenBookQA > TruthfulQA.
* **No Outliers:** The data follows a clear pattern without any anomalous spikes or drops that break the trend.
### Interpretation
This chart demonstrates the impact of model sparsification on performance across diverse reasoning and knowledge tasks. The key takeaway is that **sparsifying the OLMo-7B model results in a minor but consistent reduction in accuracy** across all tested benchmarks.
The data suggests a trade-off: the "Sparse OLMo-7B" likely offers advantages in computational efficiency (memory, speed) at the cost of a small performance penalty. The fact that the performance drop is uniform and small indicates that the sparsification technique preserves the model's core capabilities effectively. The benchmark hierarchy (PIQA being easiest, TruthfulQA hardest) reveals the relative challenges these tasks pose to this class of language models, independent of their size or sparsity.