## Bar Chart: Benchmark Comparison
### Overview
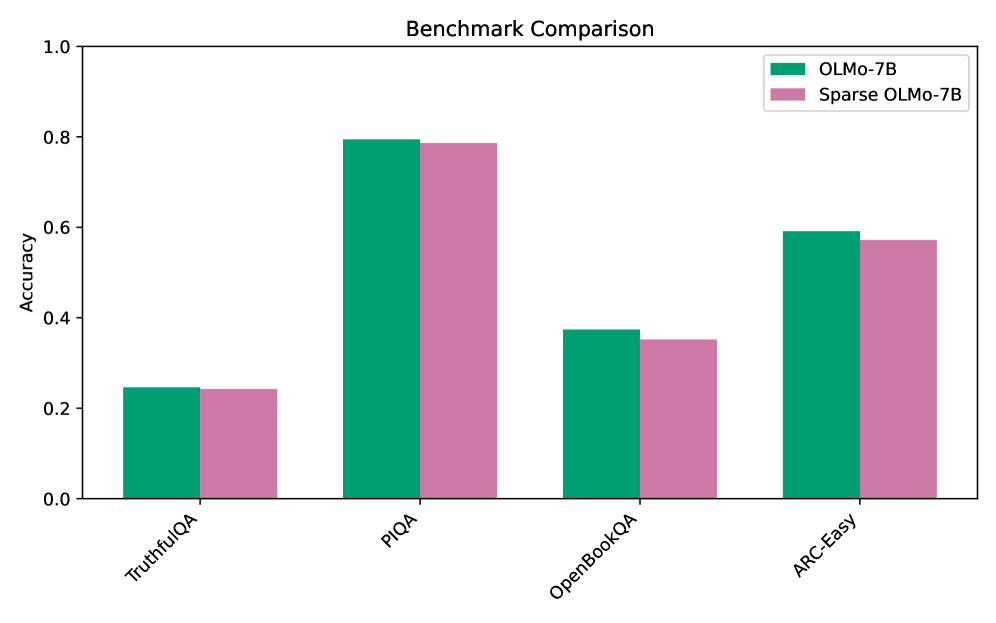
The chart compares the accuracy of two language models, **OLMo-7B** (teal) and **Sparse OLMo-7B** (pink), across four benchmarks: TruthfulQA, PIQA, OpenBookQA, and ARC-Easy. The y-axis represents accuracy (0–1), and the x-axis lists the benchmarks. Both models show higher accuracy in PIQA and ARC-Easy compared to TruthfulQA and OpenBookQA.
### Components/Axes
- **Title**: "Benchmark Comparison"
- **Legend**: Located in the top-right corner, with teal representing OLMo-7B and pink representing Sparse OLMo-7B.
- **X-axis**: Benchmarks (TruthfulQA, PIQA, OpenBookQA, ARC-Easy), evenly spaced.
- **Y-axis**: Accuracy (0–1), with increments of 0.2.
### Detailed Analysis
1. **TruthfulQA**:
- OLMo-7B: ~0.24
- Sparse OLMo-7B: ~0.24
- Both models perform nearly identically.
2. **PIQA**:
- OLMo-7B: ~0.80
- Sparse OLMo-7B: ~0.78
- OLMo-7B slightly outperforms Sparse OLMo-7B, with the largest gap observed here.
3. **OpenBookQA**:
- OLMo-7B: ~0.38
- Sparse OLMo-7B: ~0.35
- OLMo-7B maintains a small advantage.
4. **ARC-Easy**:
- OLMo-7B: ~0.60
- Sparse OLMo-7B: ~0.58
- OLMo-7B again outperforms Sparse OLMo-7B, though the difference is smaller than in PIQA.
### Key Observations
- **Consistent Performance Gap**: OLMo-7B consistently outperforms Sparse OLMo-7B across all benchmarks, with the largest difference in PIQA (~0.02) and the smallest in TruthfulQA (~0.00).
- **Benchmark-Specific Trends**:
- **PIQA**: Highest accuracy for both models (~0.80 for OLMo-7B).
- **TruthfulQA**: Lowest accuracy for both models (~0.24).
- **ARC-Easy**: Second-highest accuracy for both models (~0.60 for OLMo-7B).
### Interpretation
The data suggests that **OLMo-7B** retains a performance edge over its sparse variant, particularly in complex reasoning tasks like PIQA. The minimal difference in TruthfulQA implies that sparsity has a negligible impact on factual recall or truthfulness. However, the reduced accuracy in OpenBookQA and ARC-Easy for Sparse OLMo-7B highlights potential trade-offs in model efficiency (via sparsity) at the cost of task-specific performance. This could indicate that sparsity affects the model’s ability to handle nuanced or multi-step reasoning, depending on the benchmark’s design.