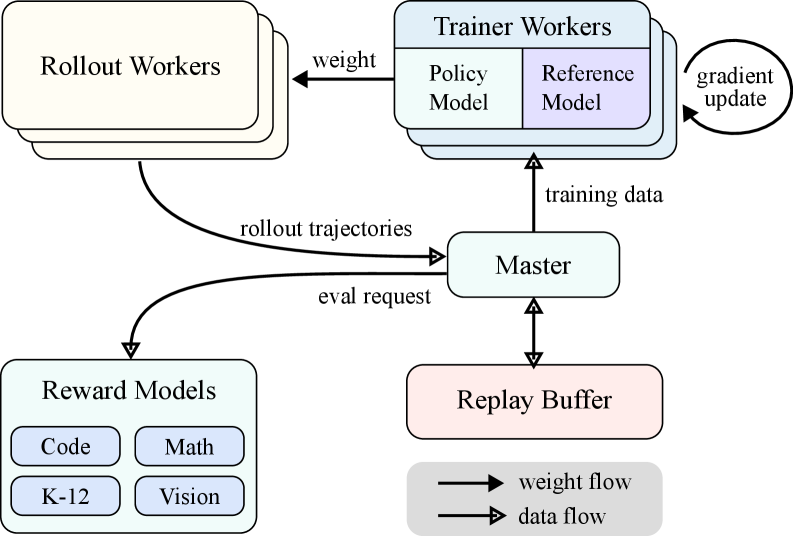
## Diagram: Reinforcement Learning System Architecture
### Overview
The image depicts a system architecture for reinforcement learning, illustrating the flow of data and weights between different components. The system includes Rollout Workers, Trainer Workers (with Policy and Reference Models), Reward Models, a Master component, and a Replay Buffer.
### Components/Axes
* **Rollout Workers:** Located at the top-left.
* **Trainer Workers:** Located at the top-center, divided into "Policy Model" (light blue) and "Reference Model" (light purple).
* **Reward Models:** Located at the bottom-left, containing "Code", "Math", "K-12", and "Vision" (all light blue).
* **Master:** Located in the center.
* **Replay Buffer:** Located at the bottom-center.
* **Legend:** Located at the bottom-right, indicating "weight flow" (arrow) and "data flow" (arrow with filled head).
### Detailed Analysis
* **Rollout Workers** send "rollout trajectories" to the "Master".
* **Rollout Workers** receive "weight" from the "Trainer Workers".
* **Master** sends "eval request" to the "Reward Models".
* **Reward Models** send data to the "Master".
* **Master** sends data to the "Replay Buffer" and receives data from it.
* **Master** sends "training data" to the "Trainer Workers".
* **Trainer Workers** send "gradient update" back into themselves.
### Key Observations
* The diagram emphasizes the iterative nature of reinforcement learning, with data flowing between components for training and evaluation.
* The separation of Trainer Workers into Policy and Reference Models suggests a specific training technique, possibly related to regularization or stability.
* The Reward Models represent different sources of feedback or evaluation signals for the learning process.
### Interpretation
The diagram illustrates a reinforcement learning system where multiple actors interact to train a policy. Rollout Workers generate experience, which is then evaluated by Reward Models. The Master orchestrates the process, sending data to the Replay Buffer and Trainer Workers. The Trainer Workers update the policy based on the training data and send updated weights back to the Rollout Workers, closing the loop. The separation of Policy and Reference Models within the Trainer Workers suggests a method to stabilize or regularize the training process, possibly by comparing the current policy to a reference policy. The different Reward Models indicate that the system can incorporate diverse feedback signals, allowing for more complex and nuanced learning.