\n
## Diagram: Reinforcement Learning System Architecture
### Overview
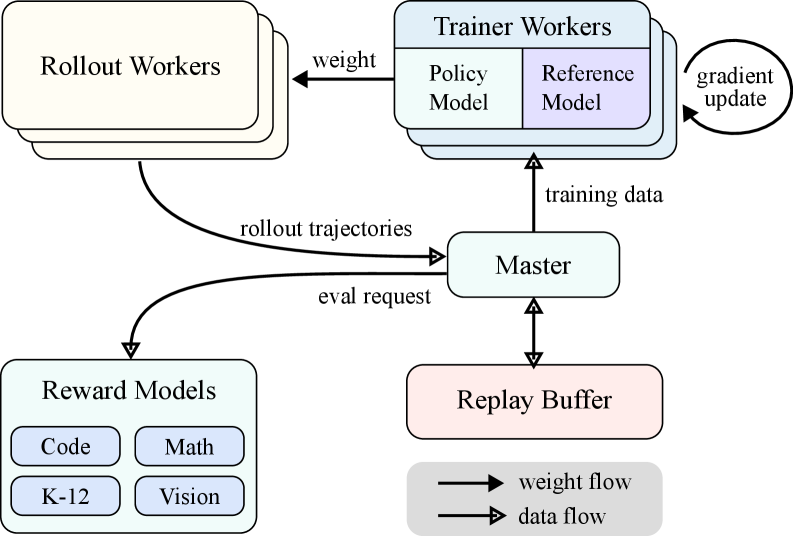
The image depicts a diagram of a reinforcement learning system architecture, illustrating the interaction between different components involved in training an agent. The diagram shows a cyclical flow of data and weights between Rollout Workers, Trainer Workers, a Master component, Reward Models, and a Replay Buffer. Arrows indicate the direction of data and weight flow.
### Components/Axes
The diagram consists of the following components:
* **Rollout Workers:** Represented by a rounded rectangle with multiple instances, suggesting parallel execution.
* **Trainer Workers:** A rounded rectangle containing two sub-components: "Policy Model" and "Reference Model".
* **Master:** A central rounded rectangle coordinating the process.
* **Reward Models:** A rounded rectangle containing four sub-components: "Code", "Math", "K-12", and "Vision".
* **Replay Buffer:** A rounded rectangle serving as a data storage.
* **Arrows:** Indicate the flow of data and weights. Two types of arrows are used: solid arrows with a filled arrowhead for weight flow, and arrows with an open arrowhead for data flow.
* **Labels:** "weight", "gradient update", "rollout trajectories", "eval request", "training data".
* **Legend:** Located in the bottom-right corner, defining the arrow types: "weight flow" (solid arrow) and "data flow" (open arrow).
### Detailed Analysis or Content Details
The diagram illustrates the following interactions:
1. **Rollout Workers to Reward Models:** Rollout trajectories are sent from the Rollout Workers to the Reward Models. This is a data flow.
2. **Rollout Workers to Trainer Workers:** Weights are sent from the Rollout Workers to the Trainer Workers. This is a weight flow.
3. **Trainer Workers to Master:** Training data is sent from the Trainer Workers to the Master. This is a data flow.
4. **Master to Replay Buffer:** Data is sent from the Master to the Replay Buffer. This is a data flow.
5. **Replay Buffer to Master:** An eval request is sent from the Replay Buffer to the Master. This is a data flow.
6. **Master to Trainer Workers:** A gradient update is sent from the Master to the Trainer Workers. This is a weight flow.
7. **Trainer Workers:** Contain a "Policy Model" and a "Reference Model".
8. **Reward Models:** Contain "Code", "Math", "K-12", and "Vision" models.
### Key Observations
The diagram highlights a distributed reinforcement learning setup. The use of multiple Rollout Workers suggests parallel environment interaction for faster data collection. The separation of Policy and Reference Models within the Trainer Workers indicates a potential architecture for learning from demonstrations or using a baseline model. The Reward Models represent different evaluation criteria or environments. The Replay Buffer is a standard component for off-policy reinforcement learning algorithms.
### Interpretation
This diagram represents a common architecture for reinforcement learning, particularly in scenarios where diverse reward signals are needed (as indicated by the multiple Reward Models). The system appears to be designed for continuous learning, with the Master component orchestrating the data flow and weight updates. The separation of concerns – rollout, training, and evaluation – allows for modularity and scalability. The inclusion of "Code", "Math", "K-12", and "Vision" within the Reward Models suggests the agent is being trained to perform tasks across a variety of domains or skill levels. The cyclical nature of the diagram emphasizes the iterative process of reinforcement learning: the agent interacts with the environment, receives rewards, updates its policy, and repeats. The diagram does not provide specific numerical data or performance metrics, but it clearly illustrates the system's structure and data flow.