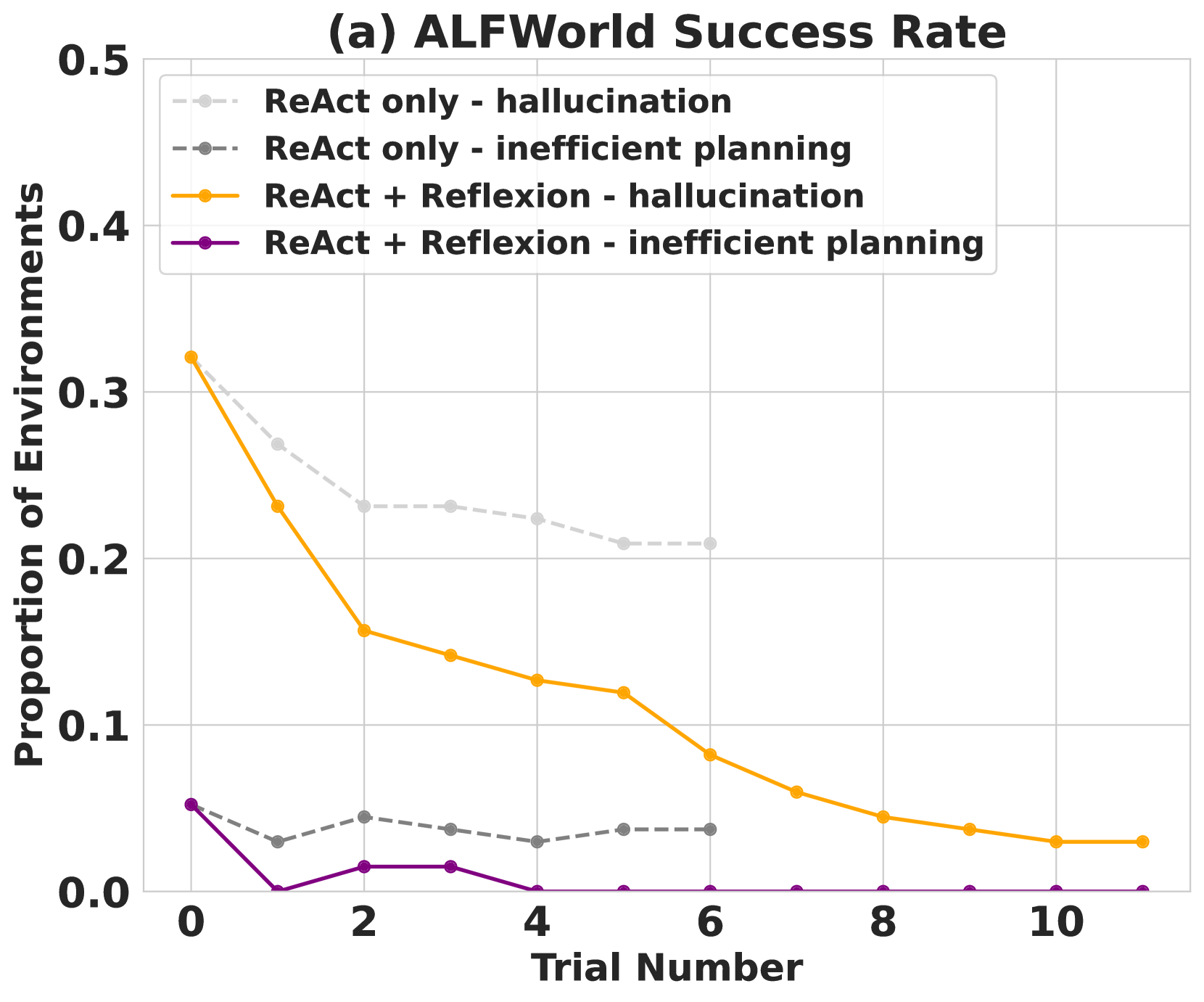
## [Line Chart]: ALFWorld Success Rate - Failure Proportions by Trial
### Overview
This is a line chart titled "(a) ALFWorld Success Rate." It plots the proportion of environments where a specific failure type occurs against the trial number for two different agent frameworks: "ReAct only" and "ReAct + Reflexion." The chart demonstrates how the frequency of two failure modes—hallucination and inefficient planning—changes over repeated trials (0 through 10).
### Components/Axes
* **Title:** (a) ALFWorld Success Rate
* **Y-Axis:** Label: "Proportion of Environments". Scale: 0.0 to 0.5, with major gridlines at 0.1 intervals.
* **X-Axis:** Label: "Trial Number". Scale: 0 to 10, with major ticks at every even number (0, 2, 4, 6, 8, 10).
* **Legend:** Located in the top-left corner of the plot area. It defines four data series:
1. `ReAct only - hallucination`: Light gray, dashed line with circle markers.
2. `ReAct only - inefficient planning`: Dark gray, dashed line with circle markers.
3. `ReAct + Reflexion - hallucination`: Orange, solid line with circle markers.
4. `ReAct + Reflexion - inefficient planning`: Purple, solid line with circle markers.
### Detailed Analysis
**Data Series Trends and Approximate Values:**
1. **ReAct + Reflexion - hallucination (Orange, Solid Line):**
* **Trend:** Shows a steep, consistent downward slope, indicating a rapid reduction in hallucination failures over trials.
* **Data Points (Approximate):**
* Trial 0: ~0.32
* Trial 1: ~0.23
* Trial 2: ~0.16
* Trial 3: ~0.14
* Trial 4: ~0.13
* Trial 5: ~0.12
* Trial 6: ~0.08
* Trial 7: ~0.06
* Trial 8: ~0.04
* Trial 9: ~0.03
* Trial 10: ~0.03
2. **ReAct only - hallucination (Light Gray, Dashed Line):**
* **Trend:** Shows a gradual downward slope, indicating a slower reduction in hallucination failures compared to the Reflexion-augmented method. The line terminates at Trial 6.
* **Data Points (Approximate):**
* Trial 0: ~0.32
* Trial 1: ~0.27
* Trial 2: ~0.23
* Trial 3: ~0.23
* Trial 4: ~0.22
* Trial 5: ~0.21
* Trial 6: ~0.21
3. **ReAct + Reflexion - inefficient planning (Purple, Solid Line):**
* **Trend:** Starts low, drops to near zero by Trial 1, has a minor resurgence at Trials 2-3, and then remains at or near zero for all subsequent trials.
* **Data Points (Approximate):**
* Trial 0: ~0.05
* Trial 1: ~0.00
* Trial 2: ~0.01
* Trial 3: ~0.01
* Trials 4-10: ~0.00
4. **ReAct only - inefficient planning (Dark Gray, Dashed Line):**
* **Trend:** Remains relatively flat and low across all visible trials (0-6), with minor fluctuations. It does not show a clear downward trend.
* **Data Points (Approximate):**
* Trial 0: ~0.05
* Trial 1: ~0.03
* Trial 2: ~0.04
* Trial 3: ~0.04
* Trial 4: ~0.03
* Trial 5: ~0.04
* Trial 6: ~0.04
### Key Observations
1. **Initial Parity, Diverging Paths:** Both "hallucination" series start at the same high proportion (~0.32) at Trial 0. The "ReAct + Reflexion" method diverges sharply downward, while the "ReAct only" method declines much more slowly.
2. **Reflexion's Impact on Hallucination:** The most significant trend is the dramatic and sustained reduction in hallucination failures when Reflexion is added to ReAct.
3. **Inefficient Planning is a Minor Issue:** For both frameworks, the proportion of environments failing due to inefficient planning is an order of magnitude lower than hallucination failures at the start.
4. **Reflexion Eliminates Inefficient Planning:** The "ReAct + Reflexion" method reduces inefficient planning failures to effectively zero after the first few trials.
5. **Data Limitation:** The "ReAct only" data series (both failure types) are only plotted up to Trial 6, preventing comparison in later trials.
### Interpretation
This chart provides strong evidence for the efficacy of the **Reflexion** technique when added to the **ReAct** framework in the ALFWorld benchmark. The data suggests that:
* **Learning from Failure:** The primary benefit of Reflexion is its ability to help the agent learn from and correct **hallucination errors** over repeated attempts. The steep decline in the orange line indicates effective iterative improvement.
* **Problem Prioritization:** The dominant failure mode at the outset is hallucination, not planning inefficiency. The Reflexion method successfully targets and mitigates this primary bottleneck.
* **Near-Optimal Planning:** Even without Reflexion, the ReAct agent's planning is relatively efficient (low failure rate). Reflexion refines this further to a negligible level.
* **Practical Implication:** For tasks in environments like ALFWorld, incorporating a reflective, self-critiquing mechanism (Reflexion) into a reasoning-action framework (ReAct) leads to substantially more reliable performance over time, primarily by curbing the agent's tendency to generate false or unsupported information (hallucinations). The chart visually argues that Reflexion enables more effective trial-and-error learning.