# Technical Diagram Analysis
## Diagram Overview
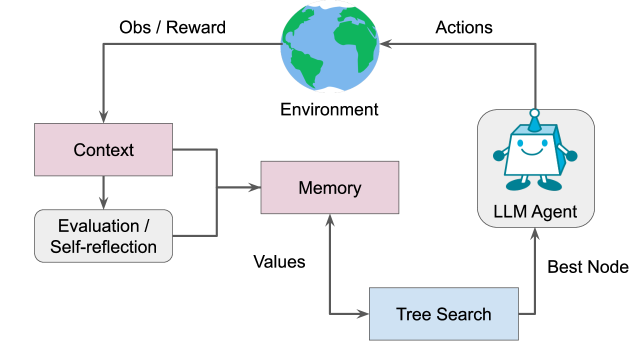
The image depicts a **flowchart** illustrating the interaction between an **LLM Agent** and its environment, emphasizing decision-making processes involving context, memory, and tree search. Key components and their relationships are detailed below.
---
## Components and Flow
### 1. **Environment**
- **Label**: "Environment" (represented by a globe icon).
- **Role**: Receives **Actions** from the LLM Agent and provides **Observations/Rewards** (Obs/Reward) to the system.
### 2. **Context**
- **Label**: "Context" (pink box).
- **Flow**:
- Receives **Obs/Reward** from the Environment.
- Outputs to **Memory** and **Evaluation/Self-reflection**.
### 3. **Memory**
- **Label**: "Memory" (pink box).
- **Flow**:
- Receives input from **Context**.
- Outputs **Values** to **Tree Search**.
### 4. **Evaluation/Self-reflection**
- **Label**: "Evaluation / Self-reflection" (gray box).
- **Flow**:
- Receives input from **Context**.
- No explicit output connections shown.
### 5. **Tree Search**
- **Label**: "Tree Search" (blue box).
- **Flow**:
- Receives **Values** from **Memory**.
- Outputs **Best Node** to the **LLM Agent**.
### 6. **LLM Agent**
- **Label**: "LLM Agent" (gray box with robot icon).
- **Flow**:
- Receives **Best Node** from **Tree Search**.
- Outputs **Actions** to the **Environment**.
### 7. **Best Node**
- **Label**: "Best Node" (text node).
- **Flow**:
- Output from **Tree Search**.
- Input to **LLM Agent**.
### 8. **Values**
- **Label**: "Values" (text node).
- **Flow**:
- Output from **Memory**.
- Input to **Tree Search**.
---
## Key Trends and Relationships
1. **Cyclical Feedback Loop**:
- The system forms a closed loop: **Environment → LLM Agent → Tree Search → Memory → Context → Evaluation/Self-reflection → Environment**.
- This suggests iterative learning and adaptation based on environmental feedback.
2. **Decision-Making Hierarchy**:
- **Tree Search** evaluates **Values** from **Memory** to determine the **Best Node**, which guides the **LLM Agent**'s actions.
- **Context** integrates observations/rewards and self-reflection to inform **Memory** and **Tree Search**.
3. **Modular Design**:
- Components are decoupled (e.g., **Evaluation/Self-reflection** operates independently of the main decision loop), enabling scalability and modular updates.
---
## Diagram Structure
- **Nodes**:
- **Input/Output Nodes**: "Obs/Reward," "Actions," "Best Node," "Values."
- **Process Nodes**: "Context," "Memory," "Tree Search," "LLM Agent," "Evaluation/Self-reflection."
- **Arrows**:
- Represent directional flow of information (e.g., "Obs/Reward" → "Context").
- No bidirectional arrows; all flows are unidirectional.
---
## Notes
- **Color Coding**:
- **Pink**: Context, Memory.
- **Gray**: Evaluation/Self-reflection, LLM Agent.
- **Blue**: Tree Search.
- **Black**: Arrows (connections).
- **Icons**:
- Globe for "Environment."
- Robot for "LLM Agent."
---
## Missing Elements
- No numerical data, heatmaps, or legends present.
- No explicit axis titles or markers (flowchart, not a chart).
---
## Summary
This flowchart models an **agent-environment interaction system** where:
1. The **LLM Agent** uses **Tree Search** to select actions based on **Memory**-derived **Values**.
2. **Context** integrates environmental feedback (**Obs/Reward**) and self-reflection to refine decision-making.
3. The system emphasizes **adaptive learning** through cyclical feedback and modular components.