# Technical Document Extraction: LLM Agent Reinforcement Learning Loop
## 1. Document Overview
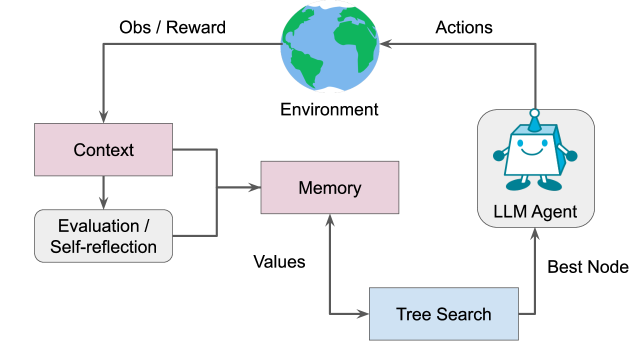
This image is a technical flow diagram illustrating the architecture of a Large Language Model (LLM) Agent interacting with an environment. It depicts a closed-loop system incorporating feedback mechanisms, memory storage, and search algorithms to optimize decision-making.
## 2. Component Isolation
### Region A: External Interface (Top)
* **Environment**: Represented by a globe icon. This is the external system or world the agent interacts with.
* **Obs / Reward**: A directed arrow flowing from the **Environment** to the **Context** block. This represents the input (Observations) and the feedback signal (Reward) received by the agent.
* **Actions**: A directed arrow flowing from the **LLM Agent** to the **Environment**. This represents the output or decisions made by the agent that affect the external state.
### Region B: Cognitive Processing (Left)
* **Context (Pink Box)**: Receives the initial "Obs / Reward" signal. It serves as the primary entry point for environmental data.
* **Evaluation / Self-reflection (Grey Rounded Box)**: Receives input from the **Context** block. This component analyzes the current state or past performance.
* **Integration Path**: Lines from both **Context** and **Evaluation / Self-reflection** merge and point toward the **Memory** block.
### Region C: Storage and Optimization (Bottom/Center)
* **Memory (Pink Box)**: A central storage component that receives integrated data from the cognitive processing blocks.
* **Tree Search (Blue Box)**: A computational component located at the bottom right.
* **Values**: A directed arrow flowing from **Memory** to **Tree Search**, indicating that stored information informs the search/optimization process.
* **Best Node**: A directed arrow flowing from **Tree Search** to the **LLM Agent**, representing the selection of the optimal path or decision found during the search.
### Region D: The Agent (Right)
* **LLM Agent (Grey Rounded Box)**: Represented by a robot icon. This is the core controller that executes the "Best Node" and outputs "Actions" back into the environment.
---
## 3. Process Flow and Logic
The diagram describes a Reinforcement Learning (RL) style loop enhanced with LLM capabilities:
1. **Perception**: The **Environment** provides an **Observation/Reward** to the **Context**.
2. **Reflection**: The agent processes this context through an **Evaluation / Self-reflection** phase.
3. **Encoding**: Both the raw context and the self-reflection are stored in **Memory**.
4. **Planning**: The **Tree Search** algorithm queries the **Memory** to retrieve **Values** (likely state-value or action-value estimates).
5. **Selection**: The search identifies the **Best Node** (the most promising next step or sequence).
6. **Execution**: The **LLM Agent** receives the selection and performs the corresponding **Actions** on the **Environment**, restarting the cycle.
---
## 4. Textual Transcriptions
| Label | Category | Description |
| :--- | :--- | :--- |
| **Environment** | Entity | The external system (Globe icon). |
| **Obs / Reward** | Data Flow | Input to the agent: Observations and Rewards. |
| **Actions** | Data Flow | Output from the agent: Decisions/Interventions. |
| **Context** | Component | Initial processing block for environmental input. |
| **Evaluation / Self-reflection** | Component | Analytical block for assessing performance/state. |
| **Memory** | Component | Storage for context and evaluations. |
| **Values** | Data Flow | Information passed from Memory to inform the search. |
| **Tree Search** | Component | Optimization/Planning algorithm. |
| **Best Node** | Data Flow | The output of the search, passed to the agent. |
| **LLM Agent** | Entity | The primary controller (Robot icon). |