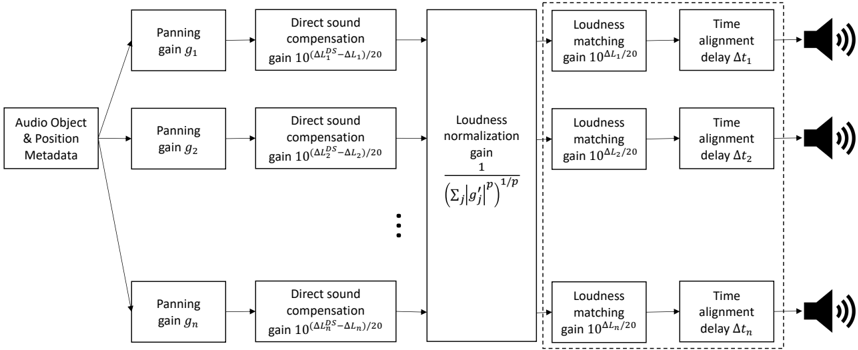
## Diagram: Spatial Audio Processing Pipeline
### Overview
The image depicts a diagram illustrating a spatial audio processing pipeline. The pipeline takes "Audio Object & Position Metadata" as input and processes it through a series of stages – Panning, Direct Sound Compensation, Loudness Normalization/Matching, and Time Alignment – to produce an audio output represented by a speaker icon. The diagram shows this process repeated for multiple audio objects, indicated by the ellipsis (...).
### Components/Axes
The diagram consists of the following components, arranged in a linear flow from left to right:
* **Input:** "Audio Object & Position Metadata"
* **Panning:** Gain denoted as *g<sub>i</sub>*, where *i* ranges from 1 to *n*.
* **Direct Sound Compensation:** Gain calculated as 10<sup>(ΔL<sub>i</sub><sup>2</sup> - ΔL<sub>1</sub>) / 20</sup>.
* **Loudness Normalization/Matching:** The first instance has a gain of 1 / (Σ|g<sub>j</sub>|<sup>p</sup>)<sup>1/p</sup>. Subsequent instances have a gain of 10<sup>ΔL<sub>i</sub> / 20</sup>.
* **Time Alignment:** Delay denoted as Δt<sub>i</sub>, where *i* ranges from 1 to *n*.
* **Output:** Speaker icon representing the audio output.
* **Ellipsis:** Indicates repetition of the processing stages for multiple audio objects.
### Detailed Analysis or Content Details
The diagram illustrates a parallel processing structure. Each audio object's metadata is processed independently through the pipeline.
1. **Audio Object & Position Metadata:** This is the initial input to the system.
2. **Panning (g<sub>i</sub>):** The audio signal is panned using a gain *g<sub>i</sub>*.
3. **Direct Sound Compensation:** A gain is applied to compensate for direct sound differences, calculated as 10<sup>(ΔL<sub>i</sub><sup>2</sup> - ΔL<sub>1</sub>) / 20</sup>. ΔL<sub>i</sub> and ΔL<sub>1</sub> represent some form of level difference.
4. **Loudness Normalization/Matching:**
* For the first audio object (i=1), a loudness normalization gain is applied: 1 / (Σ|g<sub>j</sub>|<sup>p</sup>)<sup>1/p</sup>. The summation (Σ) is over all audio objects *j*. The parameter *p* is not defined.
* For subsequent audio objects (i > 1), a loudness matching gain is applied: 10<sup>ΔL<sub>i</sub> / 20</sup>.
5. **Time Alignment (Δt<sub>i</sub>):** A time delay Δt<sub>i</sub> is applied to each audio object.
6. **Output:** The processed audio signal is outputted through a speaker.
The ellipsis indicates that this process is repeated for *n* audio objects.
### Key Observations
* The diagram highlights a parallel processing architecture for spatial audio rendering.
* The loudness normalization/matching stage appears to be crucial for maintaining consistent loudness levels across different audio objects.
* The use of gains and delays suggests that the system is manipulating the amplitude and timing of the audio signals to create a spatial impression.
* The formula for Direct Sound Compensation uses a squared difference (ΔL<sub>i</sub><sup>2</sup>), which could emphasize larger level differences.
* The parameter *p* in the loudness normalization formula is undefined, suggesting it might be a tunable parameter.
### Interpretation
This diagram represents a simplified model of a spatial audio rendering system. The core idea is to take audio objects with positional information and transform them into signals that, when played through multiple speakers, create a sense of spatial localization.
The panning stage positions the sound source in the stereo field. The direct sound compensation likely aims to account for differences in the direct sound level between the listener and each speaker. The loudness normalization/matching stage ensures that all audio objects are perceived at roughly the same loudness, regardless of their distance or position. Finally, the time alignment stage introduces delays to account for the different travel times of sound from each source to the listener, further enhancing the spatial impression.
The use of gains and delays suggests that the system is based on amplitude panning and time-delay stereophony techniques. The ellipsis indicates that the system can handle multiple audio objects simultaneously, creating a more immersive and realistic soundscape. The undefined parameter *p* suggests a degree of flexibility in the loudness normalization process, potentially allowing for different perceptual weighting schemes.