## Scatter Plot: Model Performance Comparison
### Overview
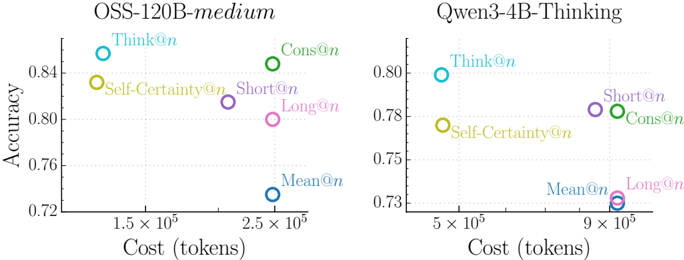
The image presents two scatter plots comparing the performance of different prompting strategies ("@n" variants) on two language models: OSS-120B-medium and Qwen-3-4B-Thinking. The plots visualize the relationship between "Cost (tokens)" and "Accuracy" for each prompting strategy.
### Components/Axes
* **X-axis (both plots):** Cost (tokens), ranging from approximately 1.5 x 10<sup>5</sup> to 9 x 10<sup>5</sup>.
* **Y-axis (both plots):** Accuracy, ranging from approximately 0.72 to 0.84.
* **Left Plot Title:** OSS-120B-medium
* **Right Plot Title:** Qwen-3-4B-Thinking
* **Data Points:** Each point represents a specific prompting strategy. The points are color-coded as follows:
* Think@n: Light Blue
* Self-Certainty@n: Orange
* Cons@n: Green
* Short@n: Violet
* Long@n: Pink
* Mean@n: Blue
### Detailed Analysis or Content Details
**Left Plot (OSS-120B-medium):**
* **Think@n:** Located at approximately (1.6 x 10<sup>5</sup>, 0.84).
* **Self-Certainty@n:** Located at approximately (1.7 x 10<sup>5</sup>, 0.82).
* **Cons@n:** Located at approximately (2.5 x 10<sup>5</sup>, 0.85).
* **Short@n:** Located at approximately (2.3 x 10<sup>5</sup>, 0.81).
* **Long@n:** Located at approximately (2.4 x 10<sup>5</sup>, 0.80).
* **Mean@n:** Located at approximately (2.5 x 10<sup>5</sup>, 0.74).
**Right Plot (Qwen-3-4B-Thinking):**
* **Think@n:** Located at approximately (5.2 x 10<sup>5</sup>, 0.81).
* **Self-Certainty@n:** Located at approximately (5.5 x 10<sup>5</sup>, 0.78).
* **Cons@n:** Located at approximately (8.5 x 10<sup>5</sup>, 0.78).
* **Short@n:** Located at approximately (8.7 x 10<sup>5</sup>, 0.79).
* **Long@n:** Located at approximately (9.0 x 10<sup>5</sup>, 0.73).
* **Mean@n:** Located at approximately (5.0 x 10<sup>5</sup>, 0.73).
### Key Observations
* For the OSS-120B-medium model, "Cons@n" exhibits the highest accuracy, while "Mean@n" has the lowest.
* For the Qwen-3-4B-Thinking model, "Think@n" has the highest accuracy, and "Long@n" has the lowest.
* The Qwen-3-4B-Thinking model generally requires a higher token cost to achieve comparable accuracy levels to the OSS-120B-medium model.
* The accuracy of "Mean@n" is consistently low across both models.
### Interpretation
The data suggests that the optimal prompting strategy varies depending on the underlying language model. For OSS-120B-medium, a "Cons@n" approach yields the best results, while for Qwen-3-4B-Thinking, "Think@n" is more effective. The difference in token cost required to achieve similar accuracy levels indicates that Qwen-3-4B-Thinking is a less efficient model in terms of cost per unit of accuracy. The consistently low performance of "Mean@n" across both models suggests that this prompting strategy is generally ineffective. The plots demonstrate a trade-off between cost and accuracy, where higher accuracy often comes at the expense of increased token usage. The positioning of the points allows for a direct comparison of the performance of each prompting strategy on each model, highlighting the model-specific effectiveness of different approaches.