\n
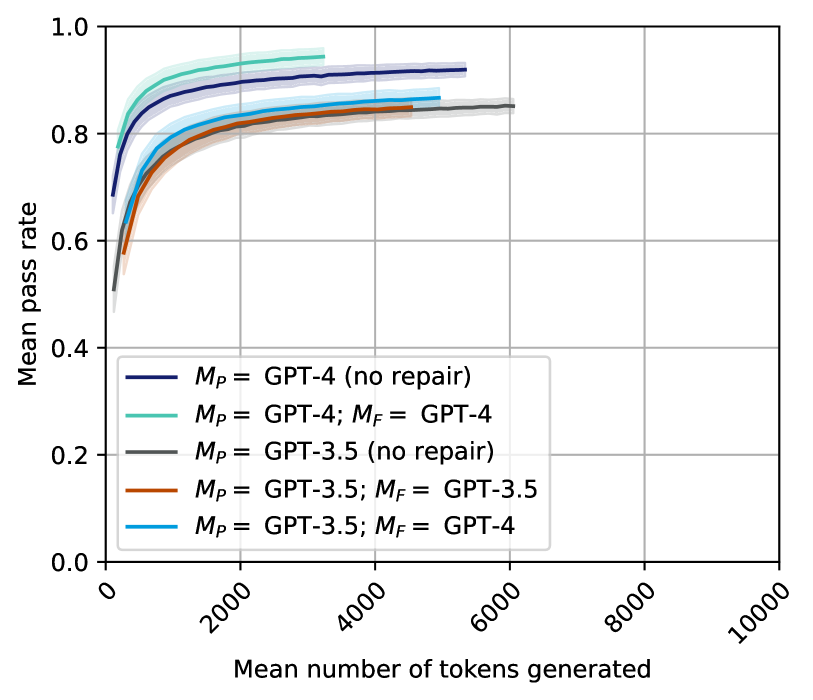
## Line Chart: Pass Rate vs. Tokens Generated
### Overview
This line chart depicts the relationship between the mean number of tokens generated and the mean pass rate for different configurations of language models (GPT-3.5 and GPT-4) with and without a "repair" step (denoted by *M<sub>P</sub>* and *M<sub>F</sub>*). The chart aims to illustrate how the performance (pass rate) of these models changes as they generate more text.
### Components/Axes
* **X-axis:** "Mean number of tokens generated". Scale ranges from 0 to 10000, with tick marks at 0, 2000, 4000, 6000, 8000, and 10000.
* **Y-axis:** "Mean pass rate". Scale ranges from 0.0 to 1.0, with tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Located in the bottom-left corner of the chart. Contains the following labels and corresponding line colors:
* Black: *M<sub>P</sub>* = GPT-4 (no repair)
* Light Blue: *M<sub>P</sub>* = GPT-4; *M<sub>F</sub>* = GPT-4
* Gray: *M<sub>P</sub>* = GPT-3.5 (no repair)
* Orange: *M<sub>P</sub>* = GPT-3.5; *M<sub>F</sub>* = GPT-3.5
* Purple: *M<sub>P</sub>* = GPT-3.5; *M<sub>F</sub>* = GPT-4
### Detailed Analysis
The chart displays five distinct lines, each representing a different model configuration.
* **Black Line (*M<sub>P</sub>* = GPT-4 (no repair)):** This line starts at approximately 0.72 and rises rapidly to around 0.85 by 2000 tokens. It then plateaus, reaching approximately 0.88 by 4000 tokens and remaining relatively stable up to 10000 tokens.
* **Light Blue Line (*M<sub>P</sub>* = GPT-4; *M<sub>F</sub>* = GPT-4):** This line begins at approximately 0.78 and exhibits a similar upward trend to the black line, but starts at a higher pass rate. It reaches approximately 0.90 by 2000 tokens and plateaus around 0.92-0.93 from 4000 to 10000 tokens.
* **Gray Line (*M<sub>P</sub>* = GPT-3.5 (no repair)):** This line starts at approximately 0.65 and increases more gradually than the GPT-4 lines. It reaches around 0.80 by 4000 tokens and continues to rise, reaching approximately 0.84 by 8000 tokens.
* **Orange Line (*M<sub>P</sub>* = GPT-3.5; *M<sub>F</sub>* = GPT-3.5):** This line begins at approximately 0.70 and shows a faster initial increase than the gray line. It reaches around 0.85 by 4000 tokens and plateaus around 0.87-0.88 from 6000 to 10000 tokens.
* **Purple Line (*M<sub>P</sub>* = GPT-3.5; *M<sub>F</sub>* = GPT-4):** This line starts at approximately 0.72 and exhibits a similar trend to the orange line, but with a slightly higher initial pass rate. It reaches approximately 0.88 by 4000 tokens and plateaus around 0.90-0.91 from 6000 to 10000 tokens.
### Key Observations
* GPT-4 consistently outperforms GPT-3.5 across all token ranges, regardless of whether a repair step is used.
* The "repair" step (using a different model for finalization, *M<sub>F</sub>*) generally improves the pass rate, particularly for GPT-3.5.
* All lines exhibit diminishing returns in pass rate as the number of tokens generated increases. The most significant improvements occur within the first 2000-4000 tokens.
* The GPT-4 model with repair (*M<sub>P</sub>* = GPT-4; *M<sub>F</sub>* = GPT-4) achieves the highest pass rates, consistently above 0.90 after 2000 tokens.
### Interpretation
The data suggests that GPT-4 is a more reliable model than GPT-3.5 for generating text that "passes" a certain criteria (the nature of which is not specified). The inclusion of a repair step, where a second model refines the output of the first, further enhances performance, especially for GPT-3.5. The diminishing returns observed at higher token counts indicate that the models' ability to maintain quality degrades as the generated text becomes longer. This could be due to factors such as context loss or increased complexity.
The use of *M<sub>P</sub>* and *M<sub>F</sub>* notation suggests a two-stage generation process. *M<sub>P</sub>* likely represents the primary model used for initial text generation, while *M<sub>F</sub>* represents a finalization model used to refine the output. The fact that using GPT-4 for both stages (*M<sub>P</sub>* = GPT-4; *M<sub>F</sub>* = GPT-4) yields the best results indicates that GPT-4 is not only a better initial generator but also a better finalizer. The improvement seen when GPT-4 is used as the finalizer for GPT-3.5 output (*M<sub>P</sub>* = GPT-3.5; *M<sub>F</sub>* = GPT-4) highlights the benefit of leveraging GPT-4's capabilities to correct or improve the output of a less powerful model.