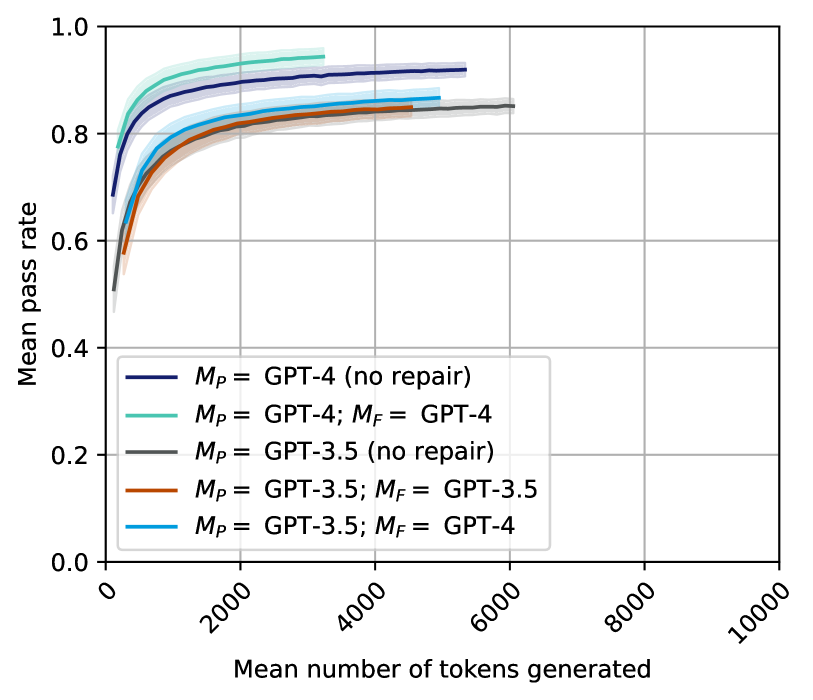
## Line Chart: Mean Pass Rate vs. Mean Number of Tokens Generated
### Overview
The chart compares the performance of different GPT model configurations in terms of mean pass rate across varying numbers of tokens generated. Five data series are plotted, differentiated by primary model (M_P) and repair model (M_F) versions. All lines exhibit sigmoidal growth patterns with plateau phases.
### Components/Axes
- **X-axis**: Mean number of tokens generated (0–10,000 tokens)
- **Y-axis**: Mean pass rate (0.0–1.0)
- **Legend**: Positioned in the bottom-left corner, with five entries:
1. Dark blue: M_P = GPT-4 (no repair)
2. Teal: M_P = GPT-4; M_F = GPT-4
3. Gray: M_P = GPT-3.5 (no repair)
4. Orange: M_P = GPT-3.5; M_F = GPT-3.5
5. Light blue: M_P = GPT-3.5; M_F = GPT-4
### Detailed Analysis
1. **Dark Blue Line (GPT-4 no repair)**:
- Starts at ~0.55 pass rate at 1,000 tokens
- Reaches plateau at ~0.92 pass rate by 4,000 tokens
- Maintains stable performance through 10,000 tokens
2. **Teal Line (GPT-4 with GPT-4 repair)**:
- Begins at ~0.60 pass rate at 1,000 tokens
- Plateaus at ~0.88 pass rate by 3,000 tokens
- Shows slight decline to ~0.86 at 6,000 tokens
3. **Gray Line (GPT-3.5 no repair)**:
- Initial pass rate ~0.50 at 1,000 tokens
- Reaches ~0.80 pass rate by 4,000 tokens
- Stabilizes at ~0.82 through 10,000 tokens
4. **Orange Line (GPT-3.5 with GPT-3.5 repair)**:
- Starts at ~0.55 pass rate at 1,000 tokens
- Peaks at ~0.78 pass rate by 4,000 tokens
- Declines to ~0.75 at 6,000 tokens
5. **Light Blue Line (GPT-3.5 with GPT-4 repair)**:
- Initial pass rate ~0.62 at 1,000 tokens
- Reaches ~0.80 pass rate by 4,000 tokens
- Maintains ~0.81 through 10,000 tokens
### Key Observations
- GPT-4 models consistently outperform GPT-3.5 across all configurations
- Repair operations reduce performance compared to no-repair scenarios
- Using GPT-4 for repair (light blue) improves GPT-3.5's performance by ~0.19 pass rate
- All models show diminishing returns after ~4,000 tokens generated
- GPT-4 no-repair achieves highest performance (0.92 pass rate)
### Interpretation
The data demonstrates that model version significantly impacts performance, with GPT-4 consistently outperforming GPT-3.5. Repair operations introduce performance degradation, but using a higher version model for repair (GPT-4) mitigates this effect. The no-repair configurations achieve the highest pass rates, suggesting that repair mechanisms may introduce inefficiencies. The plateau phases indicate that increasing token generation beyond ~4,000 tokens provides minimal performance gains. This suggests optimal resource allocation should focus on GPT-4 models with careful consideration of repair strategy tradeoffs.