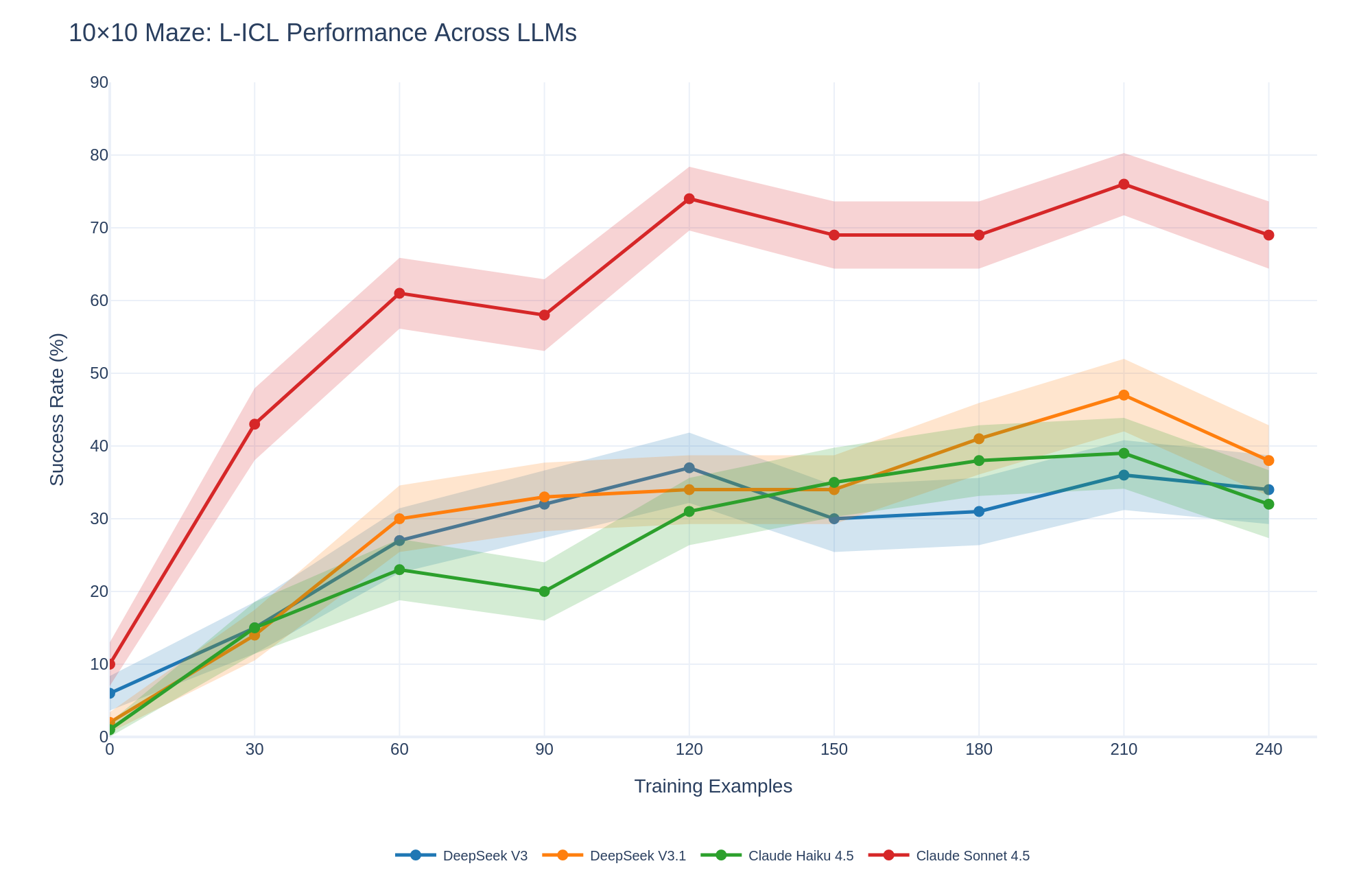
## Line Chart: 10x10 Maze: L-ICL Performance Across LLMs
### Overview
The image is a line chart comparing the performance of four different Large Language Models (LLMs) on a 10x10 maze task. The chart plots the success rate (%) of each model against the number of training examples. The models compared are DeepSeek V3, DeepSeek V3.1, Claude Haiku 4.5, and Claude Sonnet 4.5. The chart includes shaded regions around each line, representing the uncertainty or variance in the performance.
### Components/Axes
* **Title:** 10x10 Maze: L-ICL Performance Across LLMs
* **X-axis:** Training Examples
* Scale: 0 to 240, with markers at 0, 30, 60, 90, 120, 150, 180, 210, and 240.
* **Y-axis:** Success Rate (%)
* Scale: 0 to 90, with markers at 0, 10, 20, 30, 40, 50, 60, 70, 80, and 90.
* **Legend:** Located at the bottom of the chart.
* DeepSeek V3 (Blue)
* DeepSeek V3.1 (Orange)
* Claude Haiku 4.5 (Green)
* Claude Sonnet 4.5 (Red)
### Detailed Analysis
* **DeepSeek V3 (Blue):**
* Trend: Generally increasing, but plateaus and slightly decreases towards the end.
* Data Points:
* 0 Training Examples: ~2%
* 30 Training Examples: ~10%
* 60 Training Examples: ~27%
* 90 Training Examples: ~33%
* 120 Training Examples: ~37%
* 150 Training Examples: ~30%
* 180 Training Examples: ~32%
* 210 Training Examples: ~38%
* 240 Training Examples: ~35%
* **DeepSeek V3.1 (Orange):**
* Trend: Increasing, peaks around 210 training examples, then decreases.
* Data Points:
* 0 Training Examples: ~3%
* 30 Training Examples: ~12%
* 60 Training Examples: ~30%
* 90 Training Examples: ~33%
* 120 Training Examples: ~35%
* 150 Training Examples: ~38%
* 180 Training Examples: ~43%
* 210 Training Examples: ~47%
* 240 Training Examples: ~38%
* **Claude Haiku 4.5 (Green):**
* Trend: Increasing, plateaus, and slightly decreases towards the end.
* Data Points:
* 0 Training Examples: ~5%
* 30 Training Examples: ~15%
* 60 Training Examples: ~22%
* 90 Training Examples: ~18%
* 120 Training Examples: ~32%
* 150 Training Examples: ~35%
* 180 Training Examples: ~38%
* 210 Training Examples: ~35%
* 240 Training Examples: ~32%
* **Claude Sonnet 4.5 (Red):**
* Trend: Rapidly increasing initially, plateaus, and then slightly decreases.
* Data Points:
* 0 Training Examples: ~7%
* 30 Training Examples: ~43%
* 60 Training Examples: ~61%
* 90 Training Examples: ~58%
* 120 Training Examples: ~74%
* 150 Training Examples: ~69%
* 180 Training Examples: ~68%
* 210 Training Examples: ~76%
* 240 Training Examples: ~69%
### Key Observations
* Claude Sonnet 4.5 (Red) significantly outperforms the other models, achieving a much higher success rate with fewer training examples.
* DeepSeek V3 (Blue) has the lowest overall performance.
* DeepSeek V3.1 (Orange) and Claude Haiku 4.5 (Green) have similar performance trends, with DeepSeek V3.1 generally performing slightly better.
* All models show diminishing returns with increased training examples, with performance plateauing or even decreasing after a certain point.
* The shaded regions indicate variability in performance, with Claude Sonnet 4.5 showing the widest range of variability.
### Interpretation
The chart demonstrates the effectiveness of different LLMs in solving a 10x10 maze task through In-Context Learning (ICL). Claude Sonnet 4.5 exhibits superior learning capabilities, achieving high success rates with fewer training examples, suggesting a more efficient learning algorithm or a better-suited architecture for this specific task. The plateauing or decreasing performance after a certain number of training examples suggests that the models may be overfitting to the training data or reaching the limits of what can be learned through ICL for this particular maze complexity. The variability in performance, as indicated by the shaded regions, highlights the instability or sensitivity of the models to different training sets or initial conditions. The data suggests that model selection and optimization of training examples are crucial for maximizing performance in ICL tasks.