\n
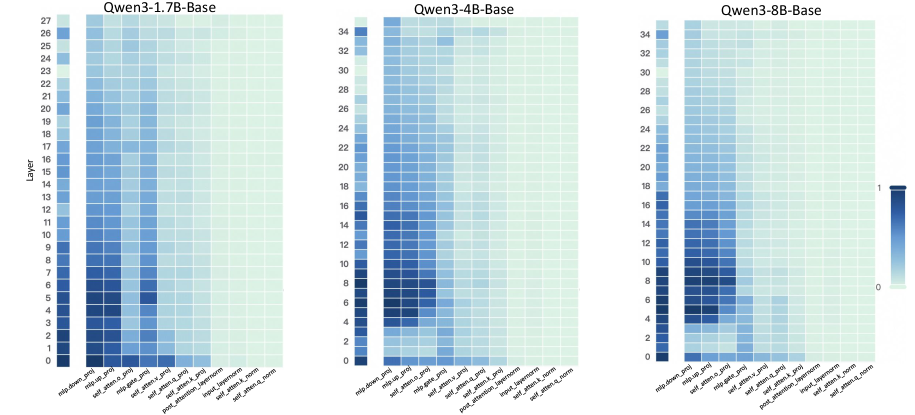
## Heatmaps: Qwen Model Layer Activation Analysis
### Overview
The image presents three heatmaps, each representing the activation levels of different layers within three Qwen language models: Qwen3-1.7B-Base, Qwen3-4B-Base, and Qwen3-8B-Base. The heatmaps visualize the relationship between model layers (vertical axis) and different attention mechanisms (horizontal axis). Color intensity represents the activation level, with darker blues indicating higher activation and lighter blues indicating lower activation.
### Components/Axes
Each heatmap shares the same structure:
* **Vertical Axis:** "Layer", ranging from 0 to 27 for Qwen3-1.7B-Base, 0 to 27 for Qwen3-4B-Base, and 0 to 27 for Qwen3-8B-Base.
* **Horizontal Axis:** Attention mechanisms, labeled as follows: "mlp_hidden_proj", "self_atten_k_proj", "self_atten_v_proj", "post_atten_layerNorm", "self_atten_o_proj".
* **Color Scale:** A gradient from light blue (approximately 0) to dark blue (approximately 1). The scale is positioned on the right side of each heatmap.
* **Titles:** Each heatmap is labeled with the corresponding model name: "Qwen3-1.7B-Base", "Qwen3-4B-Base", and "Qwen3-8B-Base".
### Detailed Analysis or Content Details
**Qwen3-1.7B-Base:**
* **Trend:** Generally, activation levels are higher in the lower layers (0-10) and decrease as the layer number increases. "mlp_hidden_proj" shows a relatively consistent activation across layers. "self_atten_k_proj", "self_atten_v_proj", and "self_atten_o_proj" show a more pronounced decrease in activation with increasing layer number. "post_atten_layerNorm" shows a slight increase in activation in the middle layers (around 10-15) before decreasing again.
* **Specific Values (approximate):**
* Layer 0, "mlp_hidden_proj": ~0.8
* Layer 0, "self_atten_k_proj": ~0.9
* Layer 10, "mlp_hidden_proj": ~0.6
* Layer 10, "self_atten_k_proj": ~0.4
* Layer 20, "mlp_hidden_proj": ~0.3
* Layer 20, "self_atten_k_proj": ~0.1
* Layer 5, "post_atten_layerNorm": ~0.5
* Layer 15, "post_atten_layerNorm": ~0.7
**Qwen3-4B-Base:**
* **Trend:** Similar to Qwen3-1.7B-Base, activation levels are generally higher in lower layers and decrease with increasing layer number. However, the overall activation levels appear slightly higher across all attention mechanisms compared to the 1.7B model. "post_atten_layerNorm" shows a more pronounced peak in activation around layers 10-15.
* **Specific Values (approximate):**
* Layer 0, "mlp_hidden_proj": ~0.9
* Layer 0, "self_atten_k_proj": ~1.0
* Layer 10, "mlp_hidden_proj": ~0.7
* Layer 10, "self_atten_k_proj": ~0.5
* Layer 20, "mlp_hidden_proj": ~0.4
* Layer 20, "self_atten_k_proj": ~0.2
* Layer 5, "post_atten_layerNorm": ~0.6
* Layer 15, "post_atten_layerNorm": ~0.8
**Qwen3-8B-Base:**
* **Trend:** The trend is consistent with the other two models – higher activation in lower layers, decreasing with depth. Activation levels are generally comparable to Qwen3-4B-Base. "post_atten_layerNorm" again shows a peak in activation around layers 10-15.
* **Specific Values (approximate):**
* Layer 0, "mlp_hidden_proj": ~0.8
* Layer 0, "self_atten_k_proj": ~0.9
* Layer 10, "mlp_hidden_proj": ~0.6
* Layer 10, "self_atten_k_proj": ~0.4
* Layer 20, "mlp_hidden_proj": ~0.3
* Layer 20, "self_atten_k_proj": ~0.1
* Layer 5, "post_atten_layerNorm": ~0.5
* Layer 15, "post_atten_layerNorm": ~0.7
### Key Observations
* All three models exhibit a similar pattern of decreasing activation levels with increasing layer depth.
* "mlp_hidden_proj" consistently shows relatively stable activation across layers.
* "post_atten_layerNorm" shows a localized peak in activation in the middle layers (around 10-15) for all three models.
* The 4B and 8B models generally have slightly higher activation levels than the 1.7B model.
### Interpretation
These heatmaps provide insights into how information flows and is processed within the Qwen models. The decreasing activation levels with depth suggest that initial layers are responsible for extracting fundamental features, while deeper layers refine and integrate these features. The consistent activation of "mlp_hidden_proj" indicates its importance in feature transformation across all layers. The peak in "post_atten_layerNorm" activation in the middle layers suggests that normalization plays a crucial role in stabilizing and optimizing the learning process at these depths.
The higher activation levels in the 4B and 8B models compared to the 1.7B model could indicate that larger models have a greater capacity to represent and process complex information. The consistent patterns across the three models suggest a shared architectural principle in how these Qwen models handle attention and normalization. Further investigation could explore the correlation between these activation patterns and the models' performance on specific tasks. The heatmaps are a valuable tool for understanding the internal workings of these large language models and identifying potential areas for optimization.