## Chart/Diagram Type: Data Table with Question/Answer Context
### Overview
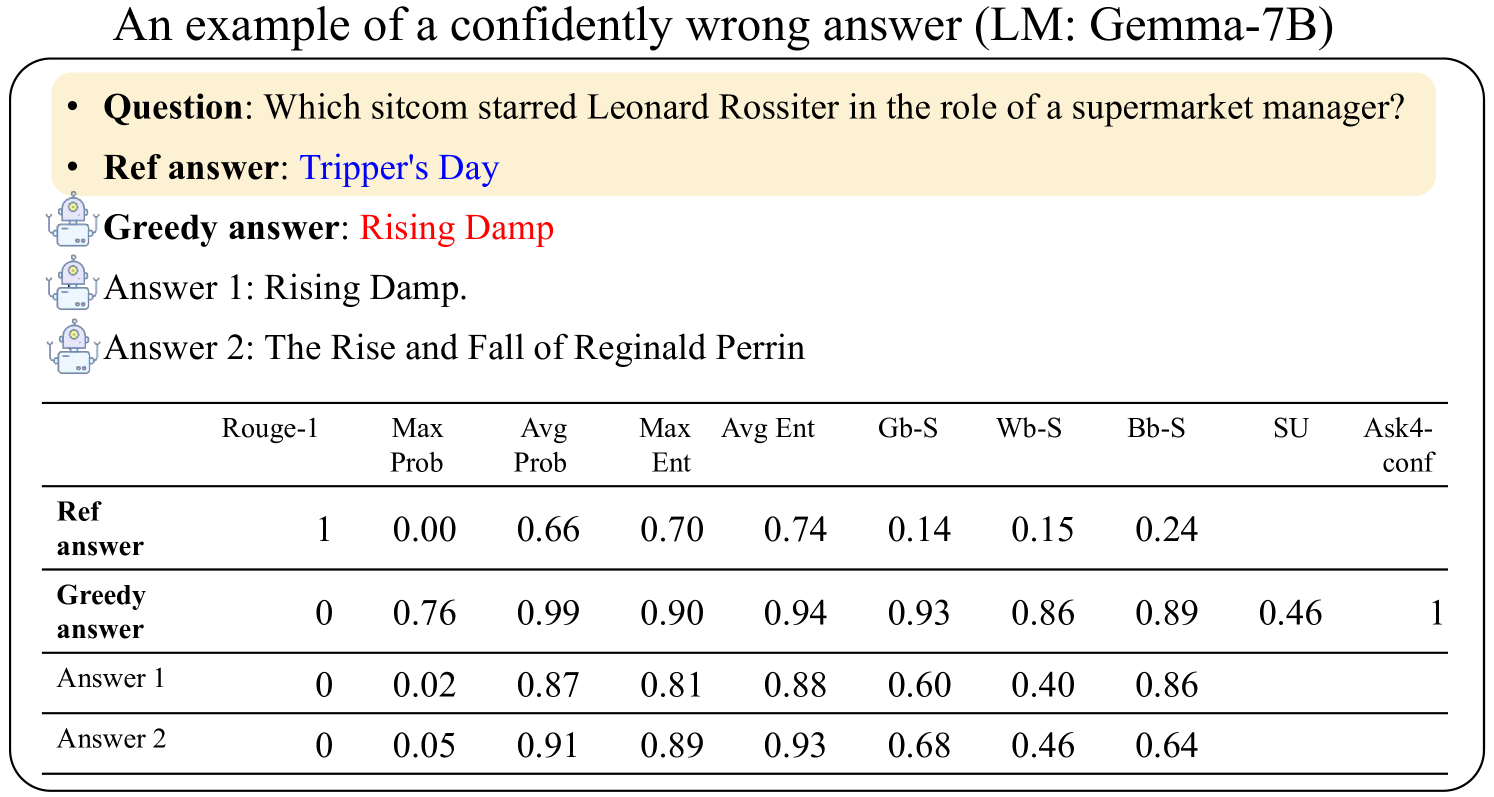
The image presents an example of a confidently wrong answer generated by a language model (LM: Gemma-7B). It includes a question, the reference answer, the model's "greedy" answer, and two additional answers. A table provides various metrics for each answer, including Rouge-1 score, maximum probability (Max Prob), average probability (Avg Prob), maximum entropy (Max Ent), average entropy (Avg Ent), and several other metrics (Gb-S, Wb-S, Bb-S, SU, Ask4-conf).
### Components/Axes
* **Title:** An example of a confidently wrong answer (LM: Gemma-7B)
* **Question:** Which sitcom starred Leonard Rossiter in the role of a supermarket manager?
* **Ref answer:** Tripper's Day
* **Greedy answer:** Rising Damp
* **Answer 1:** Rising Damp.
* **Answer 2:** The Rise and Fall of Reginald Perrin
* **Table Headers:**
* Rouge-1
* Max Prob
* Avg Prob
* Max Ent
* Avg Ent
* Gb-S
* Wb-S
* Bb-S
* SU
* Ask4-conf
* **Table Rows:**
* Ref answer
* Greedy answer
* Answer 1
* Answer 2
### Detailed Analysis or ### Content Details
The table presents the following data:
| | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
| :-------------------- | ------: | -------: | -------: | ------: | ------: | ---: | ---: | ---: | ---: | --------: |
| **Ref answer** | 1 | 0.00 | 0.66 | 0.70 | 0.74 | 0.14 | 0.15 | 0.24 | | |
| **Greedy answer** | 0 | 0.76 | 0.99 | 0.90 | 0.94 | 0.93 | 0.86 | 0.89 | 0.46 | 1 |
| **Answer 1** | 0 | 0.02 | 0.87 | 0.81 | 0.88 | 0.60 | 0.40 | 0.86 | | |
| **Answer 2** | 0 | 0.05 | 0.91 | 0.89 | 0.93 | 0.68 | 0.46 | 0.64 | | |
### Key Observations
* The "Ref answer" has a Rouge-1 score of 1, indicating it's the reference.
* The "Greedy answer" has a high average probability (0.99) and a high Ask4-conf score of 1, suggesting the model is very confident in this (incorrect) answer.
* "Answer 1" and "Answer 2" have lower maximum probabilities but relatively high average probabilities.
### Interpretation
The data demonstrates a scenario where a language model confidently provides an incorrect answer. The high "Avg Prob" and "Ask4-conf" values for the "Greedy answer" indicate that the model is highly certain about its response, despite it being wrong. This highlights a potential issue with language models: they can be confidently incorrect. The other metrics provide further insight into the characteristics of the different answers, such as their entropy and similarity to the reference answer. The Rouge-1 score confirms that only the reference answer matches the expected response.